

[ad_1]
Doc rating stays one of the crucial essential points in data retrieval & pure language processing growth. Efficient doc retrieval and rating are extremely essential in enhancing the efficiency of search engines like google and yahoo, question-answering techniques, and Retrieval-Augmented Era (RAG) techniques. Conventional rating fashions typically need assistance discovering a very good steadiness between the precision of outcomes and computational effectivity, particularly concerning large-scale datasets and a number of question sorts. As an alternative, the necessity for superior fashions with real-time potential to offer correct, contextually related outcomes from always-on streams of knowledge and ever-increasing question complexity has resurfaced, loud and clear.
Salesforce AI Analysis has launched the state-of-the-art reranker, specifically LlamaRank. This mannequin enhances the efficiency of Retrieval-Augmented Era pipelines by considerably enhancing doc rating and code search duties on numerous datasets. Having LlamaRank be based mostly on the Llama3-8B-Instruct structure successfully unites superior linear and calibrated scoring mechanisms in order to realize pace and interpretability.
The Salesforce AI Analysis crew fastidiously crafted LlamaRank as a specialised device for doc relevancy rating. Powered by iterative on-policy suggestions from their extremely devoted RLHF information annotation crew, LlamaRank does an awesome job, outperforms many main APIs normally doc rating, and redefines the state-of-the-art efficiency on code search. The coaching information contains high-quality synthesized information from Llama3-70B and Llama3-405B, together with human-labeled annotations, overlaying domains from topic-based search and doc QA to code QA.
In RAG techniques, there’s a reranker on the core, akin to LlamaRank. First, a question is processed in a really low cost however much less exact way- for instance, semantic search with embeddings- to return an inventory of candidate paperwork that could possibly be helpful. This set is refined in a extra delicate manner by the reranker to search out out which doc is most related to the question. In different phrases, this ultimate choice makes positive that the language mannequin is fine-tuned with solely probably the most related data, therefore contributing to greater accuracy and coherence within the output responses.
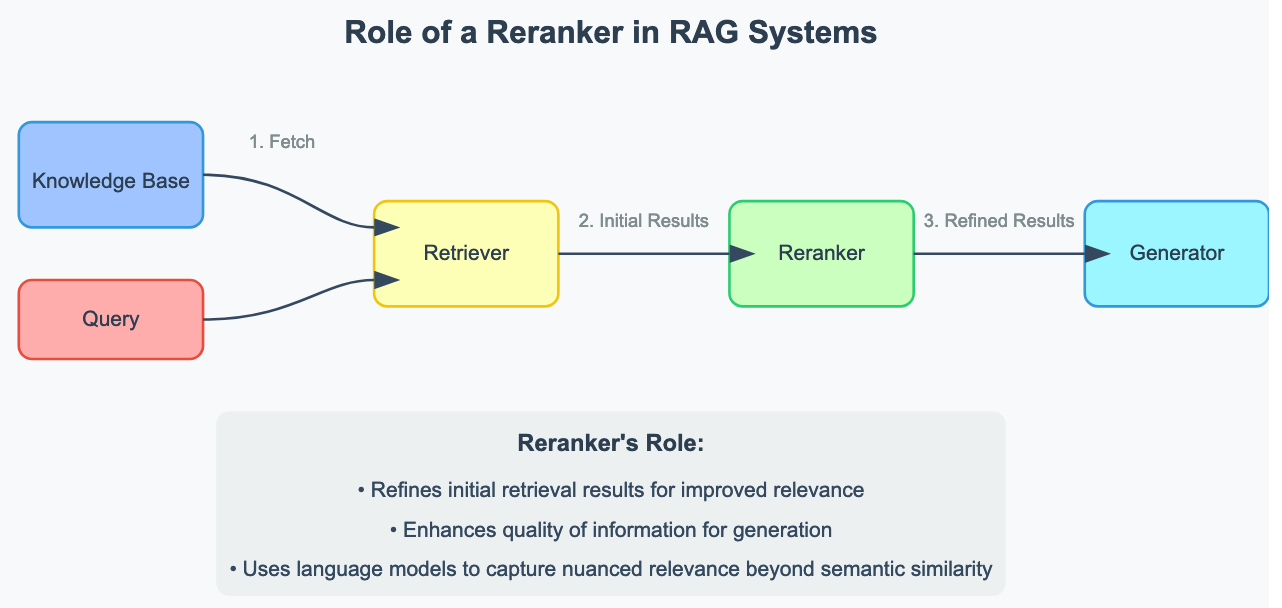
The structure of LlamaRank is constructed on prime of Llama3-8B-Instruct, the place coaching information embrace each artificial information and human-labeled examples. The huge and diversified corpus permits LlamaRank to carry out effectively on numerous duties, from normal doc retrieval to extra specialised searches for code examples. The mannequin was additional fine-tuned in a number of suggestions cycles from Salesforce’s information annotation crew till optimum accuracy and relevance had been achieved in scoring predictions. Throughout inference, the mannequin predicts the token chances and calculates a numeric relevance rating that enables for simple and environment friendly reranking.
LlamaRank has been demonstrated on a variety of public datasets and has been proven to offer sturdy outcomes on efficiency analysis. As an illustration, the well-known SQuAD dataset for query answering discovered LlamaRank racking up successful fee of 99.3%. For the TriviaQA dataset, LlamaRank posted successful fee of 92.0%. In benchmarking code search, the mannequin is evaluated when it comes to successful fee metric on the Neural Code Search dataset at successful fee of 81.8% and on the TrailheadQA dataset at successful fee of 98.6%. These outcomes underscore versatility and effectivity in dealing with a variety of doc sorts and question eventualities, which distinguishes LlamaRank.
Extra emphasizing its benefits are LlamaRank’s technical specs. The mannequin helps as much as 8,000 tokens per doc, considerably beating the competitors like Cohere’s reranker. It permits one to realize low-latency efficiency, rating 64 paperwork in beneath 200 ms with a single H100 GPU a lot quicker than the ~3.13 s on Cohere’s serverless API. On prime of that, LlamaRank has linear scoring calibration. Therefore, it’s crystal-clear regarding relevancy scores, making it higher and extra interpretable for the person.

Furthermore, LlamaRank additionally enjoys the advantages of the mannequin measurement scale and apparent prime efficiency. Nonetheless, this nice measurement, 8B parameters, could also be near the higher bounds of the reranking mannequin. Additional analysis suggests optimizing mannequin measurement to realize such a steadiness between high quality and effectivity.
Lastly, LlamaRank from Salesforce AI Analysis represents an essential leap ahead in state-of-the-art reranking know-how, which holds nice promise for considerably enhancing the effectiveness of RAG techniques throughout a variety of functions. Examined to be highly effective with excessive effectivity throughout processing and having a powerful and lucid rating set, the LlamaRank mannequin advances the strategies and state-of-the-art techniques in doc retrieval and search accuracy. The neighborhood is awaiting the adoption and growth of this LlamaRank.
Take a look at the Particulars and Strive it right here. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 50k+ ML SubReddit
Here’s a extremely really helpful webinar from our sponsor: ‘Constructing Performant AI Purposes with NVIDIA NIMs and Haystack’
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.

[ad_2]
Source link


