

[ad_1]
After the success of huge language fashions (LLMs), the present analysis extends past text-based understanding to multimodal reasoning duties. These duties combine imaginative and prescient and language, which is crucial for synthetic basic intelligence (AGI). Cognitive benchmarks akin to PuzzleVQA and AlgoPuzzleVQA consider AI’s skill to course of summary visible info and algorithmic reasoning. Even with developments, LLMs battle with multimodal reasoning, significantly sample recognition and spatial problem-solving. Excessive computational prices compound these challenges.
Prior evaluations relied on symbolic benchmarks akin to ARC-AGI and visible assessments like Raven’s Progressive Matrices. Nonetheless, these don’t adequately problem AI’s skill to course of multimodal inputs. Not too long ago, datasets like PuzzleVQA and AlgoPuzzleVQA have been launched to evaluate summary visible reasoning and algorithmic problem-solving. These datasets require fashions integrating visible notion, logical deduction, and structured reasoning. Whereas earlier fashions, akin to GPT-4-Turbo and GPT-4o, demonstrated enhancements, they nonetheless confronted limitations in summary reasoning and multimodal interpretation.

Researchers from the Singapore College of Know-how and Design (SUTD) launched a scientific analysis of OpenAI’s GPT-[n] and o-[n] mannequin collection on multimodal puzzle-solving duties. Their research examined how reasoning capabilities developed throughout totally different mannequin generations. The analysis aimed to establish gaps in AI’s notion, summary reasoning, and problem-solving expertise. The staff in contrast the efficiency of fashions akin to GPT-4-Turbo, GPT-4o, and o1 on PuzzleVQA and AlgoPuzzleVQA datasets, together with summary visible puzzles and algorithmic reasoning challenges.
The researchers carried out a structured analysis utilizing two main datasets:
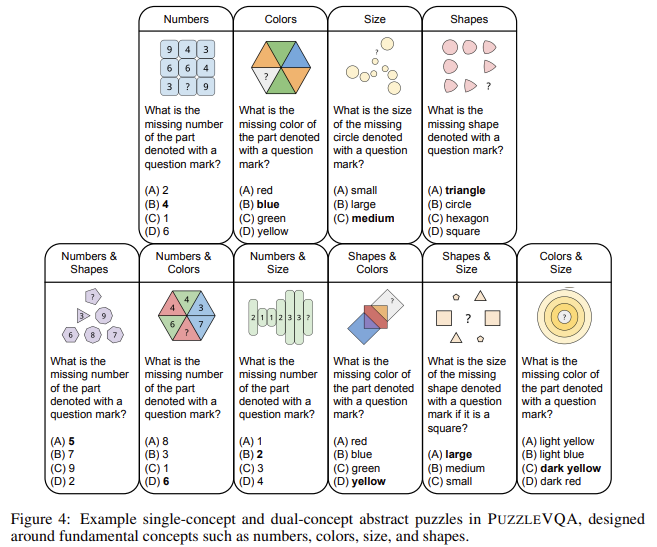
PuzzleVQA: PuzzleVQA focuses on summary visible reasoning and requires fashions to acknowledge patterns in numbers, shapes, colours, and sizes.
AlgoPuzzleVQA: AlgoPuzzleVQA presents algorithmic problem-solving duties that demand logical deduction and computational reasoning.
The analysis was carried out utilizing each multiple-choice and open-ended query codecs. The research employed a zero-shot Chain of Thought (CoT) prompting for reasoning and analyzed the efficiency drop when switching from multiple-choice to open-ended responses. The fashions had been additionally examined beneath situations the place visible notion and inductive reasoning had been individually offered to diagnose particular weaknesses.
The research noticed regular enhancements in reasoning capabilities throughout totally different mannequin generations. GPT-4o confirmed higher efficiency than GPT-4-Turbo, whereas o1 achieved essentially the most notable developments, significantly in algorithmic reasoning duties. Nonetheless, these beneficial properties got here with a pointy enhance in computational value. Regardless of total progress, AI fashions nonetheless struggled with duties that required exact visible interpretation, akin to recognizing lacking shapes or deciphering summary patterns. Whereas o1 carried out properly in numerical reasoning, it had issue dealing with shape-based puzzles. The distinction in accuracy between multiple-choice and open-ended duties indicated a powerful dependence on reply prompts. Additionally, notion remained a significant problem throughout all fashions, with accuracy bettering considerably when specific visible particulars had been offered.
In a fast recap, the work could be summarized in just a few detailed factors:
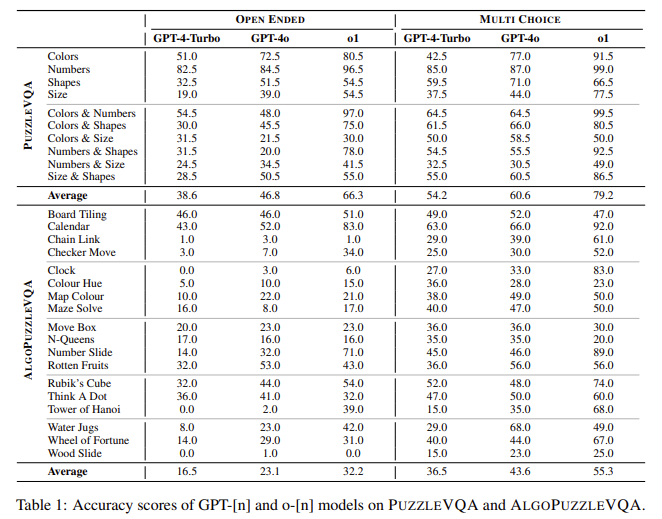
The research noticed a big upward development in reasoning capabilities from GPT-4-Turbo to GPT-4o and o1. Whereas GPT-4o confirmed average beneficial properties, the transition to o1 resulted in notable enhancements however got here at a 750x enhance in computational value in comparison with GPT-4o.
Throughout PuzzleVQA, o1 achieved a median accuracy of 79.2% in multiple-choice settings, surpassing GPT-4o’s 60.6% and GPT-4-Turbo’s 54.2%. Nonetheless, in open-ended duties, all fashions exhibited efficiency drops, with o1 scoring 66.3%, GPT-4o at 46.8%, and GPT-4-Turbo at 38.6%.
In AlgoPuzzleVQA, o1 considerably improved over earlier fashions, significantly in puzzles requiring numerical and spatial deduction. o1 scored 55.3%, in comparison with GPT-4o’s 43.6% and GPT-4-Turbo’s 36.5% in multiple-choice duties. Nonetheless, its accuracy declined by 23.1% in open-ended duties.
The research recognized notion as the first limitation throughout all fashions. Injecting specific visible particulars improved accuracy by 22%–30%, indicating a reliance on exterior notion aids. Inductive reasoning steerage additional boosted efficiency by 6%–19%, significantly in numerical and spatial sample recognition.
o1 excelled in numerical reasoning however struggled with shape-based puzzles, displaying a 4.5% drop in comparison with GPT-4o in form recognition duties. Additionally, it carried out properly in structured problem-solving however confronted challenges in open-ended situations requiring unbiased deduction.
Take a look at the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Neglect to affix our 75k+ ML SubReddit.
🚨 Beneficial Open-Supply AI Platform: ‘IntellAgent is a An Open-Supply Multi-Agent Framework to Consider Complicated Conversational AI System’ (Promoted)
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is keen about making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.
[ad_2]
Source link


