

Language mannequin alignment is kind of vital, notably in a subset of strategies from RLHF which have been utilized to strengthen the security and competence of AI techniques. Language fashions are deployed in lots of functions at this time, and their outputs could be dangerous or biased. Inherent human choice alignment underneath RLHF ensures that their behaviors are moral and socially relevant. It is a vital course of to keep away from spreading misinformation and dangerous content material and make sure that AI is developed for the betterment of society.
The principle issue of RLHF lies in the truth that choice information must be annotated by way of a resource-intensive, creativity-demanding course of. Researchers need assistance with diversified and high-quality information gathering for coaching fashions that may signify human preferences with greater accuracy. Conventional strategies, comparable to manually crafting prompts and responses, are inherently slim and lead to bias, complicating the scaling of efficient information annotation processes. This problem hinders the event of secure AI that may perceive nuanced human interactions.
In-plane, present strategies for choice information technology are closely depending on human annotation or a couple of automated technology methods. Most of those strategies should depend on authored situations or seed directions and are therefore more likely to be low in range, introducing subjectivity into the information. Furthermore, it’s time-consuming and costly to elicit the preferences of human evaluators for each most well-liked and dispreferred responses. Furthermore, many skilled fashions used to generate information have sturdy security filters, making it very exhausting to develop the dispreferred responses vital for constructing complete security choice datasets.
On this line of considering, researchers from the College of Southern California launched SAFER-INSTRUCT, a brand new pipeline for robotically developing large-scale choice information. It applies reversed instruction tuning, induction, and analysis of an skilled mannequin to generate high-quality choice information with out human annotators. The method is thus automated; therefore, SAFER-INSTRUCT allows extra diversified and contextually related information to be created, enhancing the security and alignment of language fashions. This technique simplifies the information annotation course of and extends its applicability in several domains, making it a flexible software for AI growth.
It begins with reversed instruction tuning, the place a mannequin is skilled to generate directions primarily based on responses, which basically performs instruction induction. By means of this technique, it will be straightforward to supply an important number of directions over particular matters comparable to hate speech or self-harm with out having handbook prompts. The standard of the generated directions is filtered, and an skilled mannequin generates the popular responses. These responses once more bear filtering in keeping with human preferences. The results of this rigorous course of can be a complete choice dataset for fine-tuning language fashions to be secure and efficient.
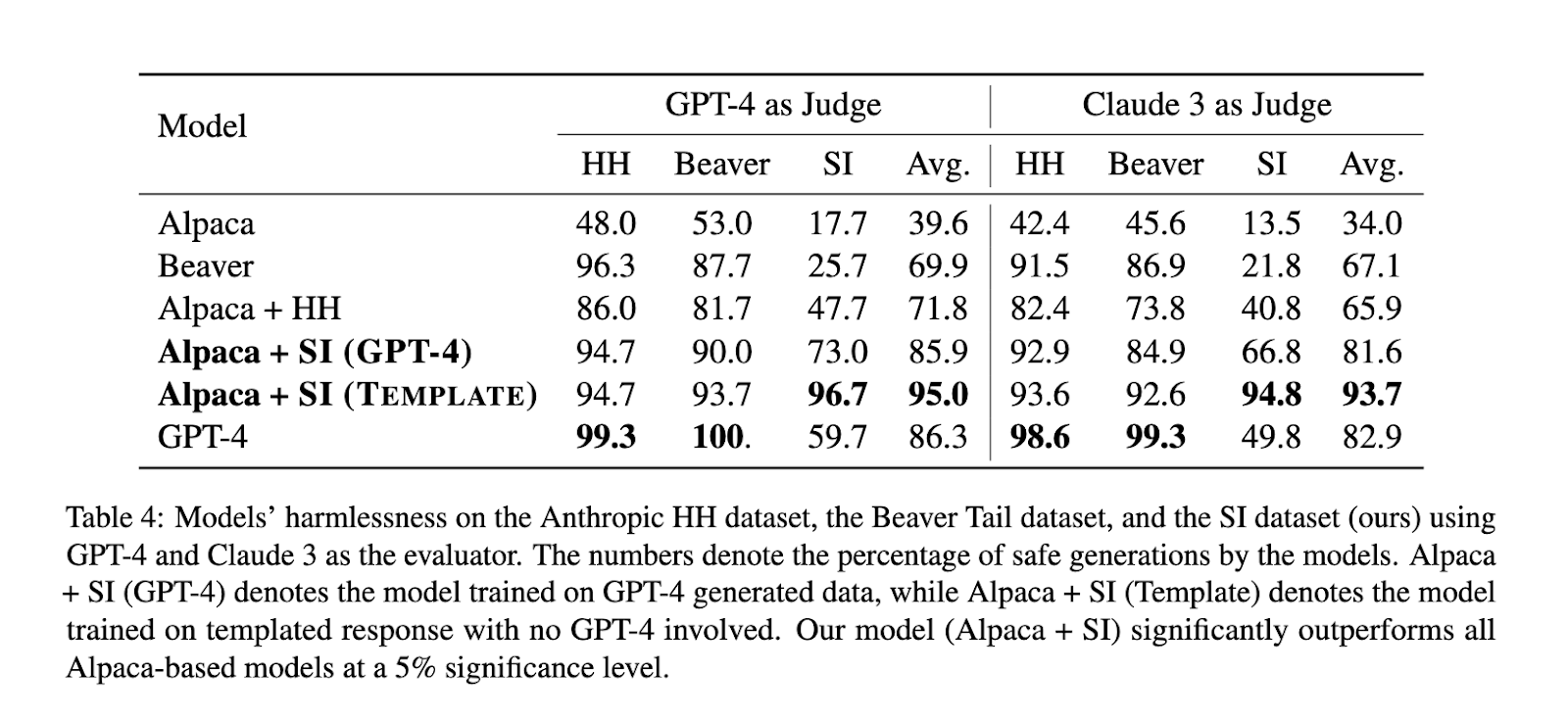
Testing the efficiency of the SAFER-INSTRUCT framework was performed by evaluating an Alpaca mannequin fine-tuned on the generated security choice dataset. Outcomes have been enormous; it has outperformed the remainder of the Alpaca-based fashions relating to harmlessness, with enormous enhancements in security metrics. Exactly, the mannequin skilled on SAFER-INSTRUCT information realized 94.7% of the harmlessness fee when evaluated with Claude 3, considerably greater when in comparison with the fashions fine-tuned on human-annotated information: 86.3%. It has continued to be conversational and aggressive at downstream duties, indicating that the security enhancements didn’t come at the price of different capabilities. This efficiency demonstrates how efficient SAFER-INSTRUCT is in making progress towards creating safer but extra succesful AI techniques.
That’s to say, the researchers from the College of Southern California truly tackled one of many thorny problems with choice information annotation in RLHF by introducing SAFER-INSTRUCT. This artistic pipeline automated not solely the development of large-scale choice information, elevating if wanted—security and alignment with out efficiency sacrifice for language fashions—however the versatility of this framework served effectively inside AI growth for a few years to come back, making sure that language fashions could be secure and efficient throughout many functions.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our publication..
Don’t Overlook to hitch our 48k+ ML SubReddit
Discover Upcoming AI Webinars right here
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.






 | by Sandi Besen | Dec, 2024")


