

[ad_1]
Ever really feel overwhelmed by the avalanche of audio content material bombarding you day by day? Podcasts pile up, assembly recordings linger in your inbox, and that fascinating lecture you missed is trapped in a video file. The sheer quantity of spoken info may be paralyzing, leaving you craving for a solution to seize its essence with out drowning within the particulars. Nicely, there’s a method. OpenAI’s Whisper can immediately transcribe any audio file with pinpoint accuracy and generate concise summaries of hour-long audio information, extracting the important thing factors with easy ease.
Whisper: An Open AI Mannequin for Textual content-to-Speech Conversion
Whisper’s energy lies in its superior neural community structure and entry to an enormous dataset of numerous audio and textual content. This interprets into a number of key options:
Multilingual Capabilities: Break down language boundaries and analyze content material in quite a few languages, from informal conversations to technical jargon.
Transcription Accuracy: Decrease errors and guarantee near-flawless transcripts, excellent for analysis, authorized proceedings, and accessibility functions.
Area Adaptability: Precisely transcribe lectures, interviews, and even technical recordings with excessive constancy.
How It Works
Whisper makes use of the Transformer structure, a neural community with consideration mechanisms for studying relationships between enter and output sequences. It contains two key elements: an encoder and a decoder.
The encoder processes audio enter, changing it into 30-second chunks, reworking it right into a log-Mel spectrogram, and encoding it into hidden vectors.
The decoder takes these vectors and predicts the corresponding textual content output. It employs particular tokens for varied duties like language identification, phrase-level timestamps, multilingual speech transcription, and to-English speech translation.
Why It Is Higher
Whisper has a number of benefits over present TTS (Textual content-to-speech) methods.
Skilled on a various dataset of 680,000 hours of audio and textual content, masking varied domains, accents, background noises, and technical languages.
Handles a number of languages and duties with a single mannequin, routinely figuring out the language of enter audio and switching duties accordingly.
Demonstrates excessive accuracy and efficiency in speech recognition, outperforming specialised fashions on numerous datasets.
A Pattern Utility (Audio to Textual content Summarization utilizing Whisper and BART)
We carried out the Whisper Mannequin to transcribe and summarize video/audio content material utilizing OpenAI’s BART summarization fashions. This performance may be invaluable for transcribing assembly notes, name recordings, or any movies/audio, saving appreciable time.
Strategy:
Develop UI utilizing Streamlit, offering a YouTube URL as enter.
Use Pytube to extract audio from the video file.
Use the Whisper mannequin to transcribe the audio into textual content.
Use the BartTokenizer/TextDavinci Mannequin to phase the textual content into chunks.
Use the Bart Mannequin to summarize the chunks and generate an output.
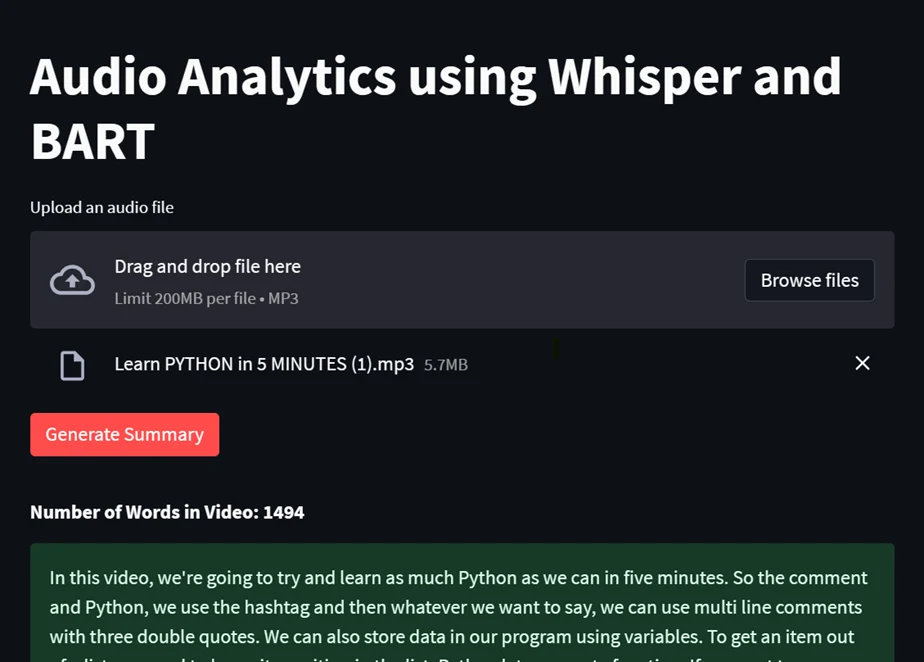
Pattern output:
1. a)
1. b)
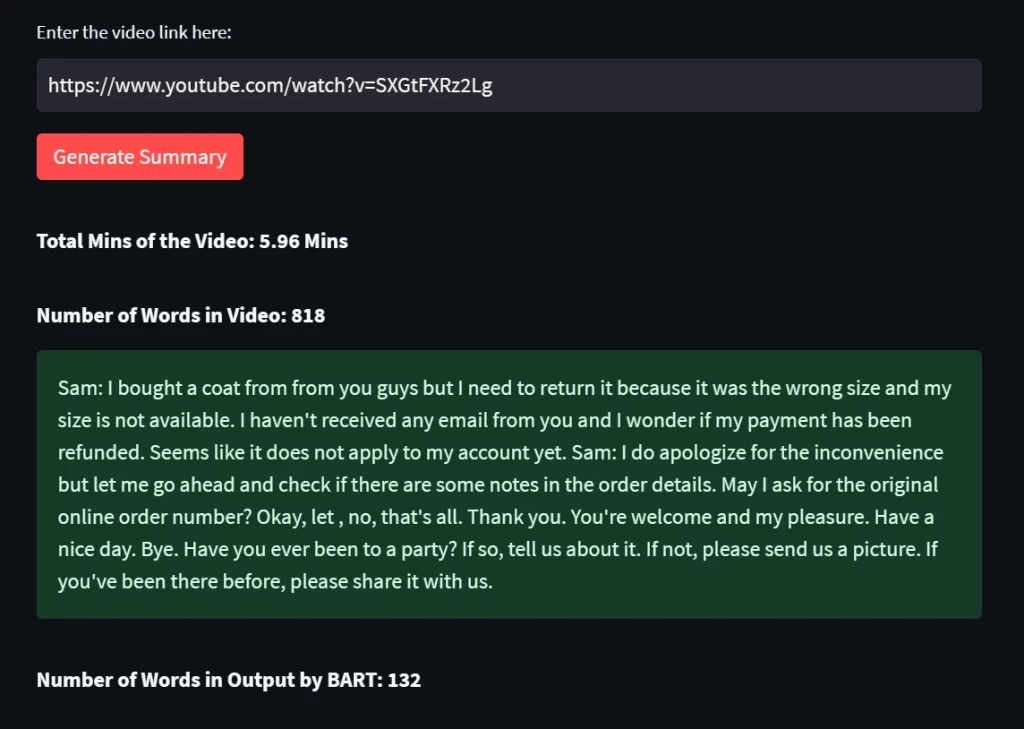
Limitations of Whisper
Whereas Whisper is a strong audio analytics answer, it has some limitations:
Works higher on GPU machines.
Hallucinations could happen throughout prolonged audio silence, complicated the decoder.
Restricted to processing 30 seconds of audio at a time.
Use Instances Throughout Industries
Whisper’s functions lengthen far past easy transcription. Listed below are only a few examples:
Transcription Companies: Companies can leverage Whisper’s API to supply quick, correct, and cost-effective transcriptions in varied languages, catering to a various clientele.
Language Studying: Observe your accent refinement by evaluating your speech to Whisper’s flawless outputs.
Buyer Service: Analyze buyer calls in actual time, perceive their wants, and enhance service primarily based on their suggestions.
Market Analysis: Collect real-time suggestions from buyer interviews, focus teams, and social media mentions, extracting priceless insights that inform product growth and advertising methods.
Voice-based Search: Develop revolutionary voice-activated serps that perceive and reply to customers in a number of languages.
Conclusion:
OpenAI’s Whisper represents a big leap ahead in audio understanding, empowering people and companies to unlock the wealth of data embedded inside spoken phrases. With its unparalleled accuracy, multilingual capabilities, and numerous functions, Whisper can reshape how we work together with and extract worth from audio content material.
[ad_2]
Source link


