

[ad_1]
Mathematical Giant Language Fashions (LLMs) have demonstrated robust problem-solving capabilities, however their reasoning means is commonly constrained by sample recognition fairly than true conceptual understanding. Present fashions are closely primarily based on publicity to related proofs as a part of their coaching, confining their extrapolation to new mathematical issues. This constraint restricts LLMs from participating in superior mathematical reasoning, particularly in issues requiring the differentiation between carefully associated mathematical ideas. A complicated reasoning technique generally missing in LLMs is the proof by counterexample, a central methodology of disproving false mathematical assertions. The absence of ample technology and employment of counterexamples hinders LLMs in conceptual reasoning of superior arithmetic, therefore diminishing their reliability in formal theorem verification and mathematical exploration.
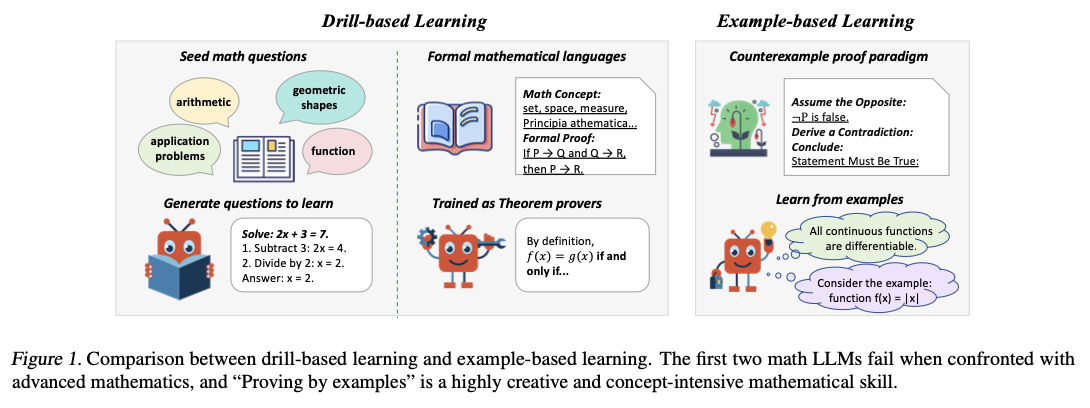
Earlier makes an attempt to enhance mathematical reasoning in LLMs have been categorized into two basic approaches. The primary strategy, artificial drawback technology, trains LLMs on huge datasets generated from seed math issues. For instance, WizardMath makes use of GPT-3.5 to generate issues of various ranges of issue. The second strategy, formal theorem proving, trains fashions to work with proof techniques similar to Lean 4, as in Draft-Sketch-Show and Lean-STaR, that help LLMs in structured theorem proving. Though these approaches have enhanced problem-solving means, they’ve extreme limitations. Artificial query technology generates memorization and never real understanding, leaving fashions susceptible to failure within the face of novel issues. Formal theorem-proving methods, then again, are restricted by being grounded in structured mathematical languages that restrict their software to varied mathematical contexts. These limitations underscore the necessity for an alternate paradigm—a paradigm that’s involved with conceptual understanding versus sample recognition.
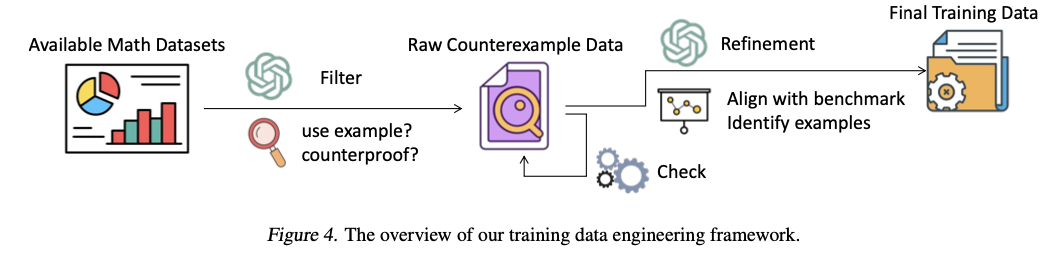
To handle these limitations, a counterexample-driven mathematical reasoning benchmark is launched, often known as COUNTERMATH. The benchmark is particularly constructed to evaluate and improve LLMs’ use of counterexamples in proof. The improvements embody a high-quality benchmark, knowledge engineering course of, and thorough mannequin assessments. COUNTERMATH is comprised of 1,216 mathematical assertions, every of which wants a counterexample to disprove. The issues are hand-curated from college textbooks and extensively validated by consultants. To reinforce LLMs’ counterexample-based reasoning, an automatic data-gathering course of is applied, filtering and refining mathematical proof knowledge to acquire counterexample-based reasoning examples. The efficacy of state-of-the-art mathematical LLMs, similar to OpenAI’s o1 mannequin and fine-tuned open-source variants, is rigorously examined on COUNTERMATH. By diverting the main focus towards example-based reasoning from unique theorem-proving, this methodology initiates a novel and under-explored path to coaching mathematical LLMs.

COUNTERMATH is constructed primarily based on 4 core mathematical disciplines: Algebra, Topology, Actual Evaluation, and Purposeful Evaluation. The info is inbuilt a multi-step course of. First, mathematical statements are gathered from textbooks and transformed to structured knowledge by way of OCR. Mathematicians then overview and annotate every drawback for logical consistency and accuracy. Skilled translations are carried out as the unique knowledge is in Chinese language, adopted by extra checks. An in-task knowledge engineering framework can be offered to routinely retrieve coaching knowledge for counterexample-based reasoning. GPT-4o filtering and refinement methods are utilized on this framework to extract related proofs from outdoors sources similar to ProofNet and NaturalProof. Refinement is completed to make sure every proof explicitly illustrates counterexamples in order that LLMs can study counterexample-based reasoning extra successfully.
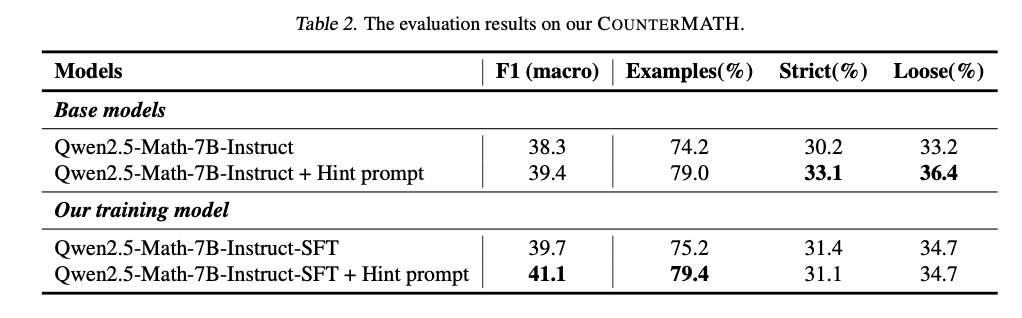
The analysis of state-of-the-art mathematical LLMs on COUNTERMATH reveals vital gaps in counterexample-driven reasoning. Nearly all of the fashions don’t cross judgment on whether or not a press release is true or false utilizing counterexamples, reflecting a profound conceptual weak point. Efficiency can be blended throughout mathematical areas, with algebra and purposeful evaluation performing higher, and topology and actual evaluation nonetheless being very difficult on account of their summary nature. Open-source fashions carry out worse than proprietary fashions, with just a few having average conceptual reasoning. Effective-tuning with counterexample-based knowledge, nevertheless, considerably enhances efficiency, with higher judgment accuracy and example-based reasoning. A fine-tuned mannequin, with just one,025 counterexample-based coaching samples, performs considerably higher than its baseline variations and has robust generalization to out-of-distribution mathematical checks. An in depth analysis reported in Desk 1 under reveals efficiency comparisons primarily based on F1 scores and reasoning consistency metrics. Qwen2.5-Math-72B-Instruct performs greatest (41.8 F1) amongst open-source fashions however falls behind proprietary fashions like GPT-4o (59.0 F1) and OpenAI o1 (60.1 F1). Effective-tuning results in vital features, with Qwen2.5-Math-7B-Instruct-SFT + Trace immediate reaching 41.1 F1, affirming the effectiveness of counterexample-based coaching.

This proposed methodology presents COUNTERMATH, a counterexample-based reasoning benchmark designed to enhance LLMs’ conceptual mathematical talents. The utilization of well-curated drawback units and an automatic knowledge refinement course of demonstrates that current LLMs will not be proficient in deep mathematical reasoning however might be enormously enhanced with counterexample-based coaching. These outcomes indicate that future AI analysis must be targeted on enhancing conceptual understanding and never exposure-based studying. Counterexample reasoning shouldn’t be solely important in arithmetic but in addition in logic, scientific investigation, and formal verification, and this methodology can thus be prolonged to a broad number of AI-driven analytical duties.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, be at liberty to comply with us on Twitter and don’t overlook to hitch our 75k+ ML SubReddit.
🚨 Really useful Learn- LG AI Analysis Releases NEXUS: An Superior System Integrating Agent AI System and Knowledge Compliance Requirements to Deal with Authorized Considerations in AI Datasets
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s enthusiastic about knowledge science and machine studying, bringing a powerful educational background and hands-on expertise in fixing real-life cross-domain challenges.

[ad_2]
Source link


