

Multimodal Massive Language Fashions (MLLMs) have made vital progress in varied purposes utilizing the ability of Transformer fashions and their consideration mechanisms. Nonetheless, these fashions face a crucial problem of inherent biases of their preliminary parameters, referred to as modality priors, which may negatively influence output high quality. The eye mechanism, which determines how enter info is weighted to generate outputs, is particularly inclined to those biases. Each visible encoder consideration and Massive Language Mannequin (LLM) spine consideration are affected by their respective priors, which may result in issues like multimodal hallucinations and degraded mannequin efficiency. Researchers are specializing in addressing these biases with out altering the mannequin’s weights.
Current developments in MLLMs have led to the event of complicated fashions like VITA and Cambrian-1, that may course of a number of modalities and obtain state-of-the-art efficiency. Analysis has additionally centered on training-free reasoning stage enhancements, comparable to VCD and OPERA, which use human expertise to reinforce mannequin efficiency with out further coaching. Efforts to handle modality priors have included strategies to beat language priors by integrating visible modules and growing benchmarks like VLind-Bench to measure language priors in MLLMs. Visible priors have been tackled by augmenting off-the-shelf LLMs to assist multimodal inputs and outputs by way of cost-effective coaching methods.
Researchers from The Hong Kong College of Science and Know-how (Guangzhou), The Hong Kong College of Science and Know-how, Nanyang Technological College, and Tsinghua College have proposed CAUSALMM, a causal reasoning framework designed to handle the challenges posed by modality priors in MLLMs. This strategy builds a structural causal mannequin for MLLMs and makes use of intervention and counterfactual reasoning strategies beneath the backdoor adjustment paradigm. This helps the proposed technique to raised seize the causal influence of efficient consideration on MLLM output, even within the presence of confounding elements comparable to modality priors. It additionally ensures that mannequin outputs align extra carefully with multimodal inputs and mitigate the detrimental results of modal priors on efficiency.
CAUSALMM’s effectiveness is evaluated utilizing benchmarks VLind-Bench, POPE, and MME. The framework is examined in opposition to baseline MLLMs like LLaVa-1.5 and Qwen2-VL, in addition to training-free methods comparable to Visible Contrastive Decoding (VCD) and Over-trust Penalty and Retrospection-Allocation (OPERA). VCD mitigates object hallucinations, whereas OPERA introduces a penalty time period throughout beam search and incorporates a rollback technique for token choice. Furthermore, the analysis consists of ablation research for various classes of counterfactual consideration and the variety of intervention layers, offering an in depth evaluation of CAUSALMM’s efficiency throughout varied eventualities and configurations.
Experimental outcomes throughout a number of benchmarks present CAUSALMM’s effectiveness in balancing modality priors and mitigating hallucinations. On VLind-Bench, it achieves vital efficiency enhancements for each LLaVA1.5 and Qwen2-VL fashions, successfully balancing visible and language priors. In POPE benchmark exams, CAUSALMM outperformed current baselines in mitigating object-level hallucinations throughout random, widespread, and adversarial settings, with a mean metric enchancment of 5.37%. The MME benchmark outcomes confirmed that the proposed technique considerably enhanced the efficiency of LLaVA-1.5 and Qwen2-VL fashions, significantly in dealing with complicated queries like counting.
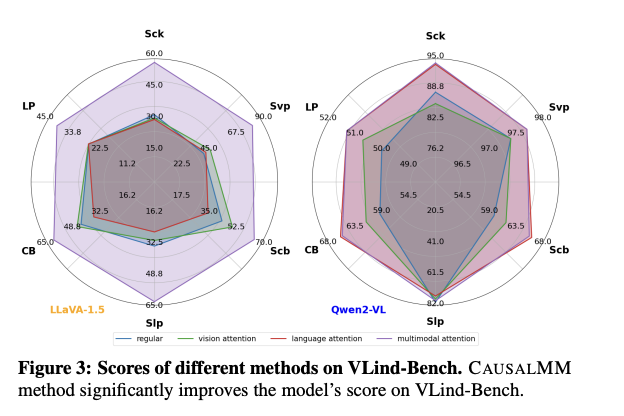
In conclusion, researchers launched CAUSALMM to handle the challenges confronted by modality priors in MLLMs. By treating modality priors as confounding elements and making use of structural causal modeling, CAUSALMM successfully mitigates biases from visible and language priors. The framework’s use of backdoor adjustment and counterfactual reasoning at visible and language consideration ranges demonstrated reductions in language prior bias throughout varied benchmarks. This modern strategy not solely improves the alignment of multimodal inputs but in addition units the inspiration for extra dependable multimodal intelligence, marking a promising path for future analysis and growth within the MLLMs area.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our publication.. Don’t Neglect to hitch our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Information Retrieval Convention (Promoted)

Sajjad Ansari is a remaining 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a concentrate on understanding the influence of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.


: A New Attention Method which Allows LLMs to Condition their Attention Weights on Multiple Query and Key Vectors")



 better choices for investors than Shiba Inu (SHIB) in 2024?")


{kind=link}