

The issue of a mediator studying to coordinate a bunch of strategic brokers is taken into account via motion suggestions with out understanding their underlying utility features, corresponding to routing drivers via a street community. The problem lies within the issue of manually specifying the standard of those suggestions, making it obligatory to offer the mediator with information on desired coordination habits. This transforms the issue into one among multi-agent imitation studying (MAIL). A basic query in MAIL is figuring out the precise goal for the learner, explored via the event of personalised route suggestions for customers.
Present analysis to unravel the challenges in multi-agent imitation studying contains a number of methodologies. Single-agent imitation Studying strategies like behavioral cloning scale back imitation to supervised studying however undergo from covariate shifts, resulting in compounding errors. Interactive approaches like inverse reinforcement studying (RL) enable learners to watch the implications of their actions, stopping compounding errors however are sample-inefficient. The subsequent strategy is multi-agent imitation studying by which the idea of the remorse hole has been explored however not utilized absolutely in Markov Video games. The third strategy, Inverse sport principle focuses on recovering utility features reasonably than studying coordination from demonstrations.
Researchers from Carnegie Mellon College have proposed another goal for multi-agent imitation studying (MAIL) in Markov Video games known as the remorse hole, which explicitly accounts for potential deviations by brokers within the group. They investigated the connection between the worth and remorse gaps, displaying that whereas the worth hole may be minimized utilizing single-agent imitation studying (IL) algorithms, it doesn’t forestall the remorse hole from changing into arbitrarily massive. This discovering signifies that attaining remorse equivalence is tougher than attaining worth equivalence in MAIL. To handle this, two environment friendly reductions are developed to no-regret on-line convex optimization, (a) MALICE, below a protection assumption on the professional, and (b) BLADES, with entry to a queryable professional.
Though the worth hole is taken into account a ‘weaker’ goal, it may be an affordable studying goal in real-world functions the place brokers are non-strategic. The pure multi-agent generalization of single-agent imitation studying algorithms can effectively reduce the worth hole, making it comparatively simple to attain in MAIL. Two such single-agent IL algorithms, Habits Cloning (BC) and Inverse Reinforcement Studying (IRL), are used to reduce the worth hole. These algorithms run over joint insurance policies the place BC and IRL are utilized to the multi-agent setting, changing into Joint Habits Cloning (J-BC) and Joint Inverse Reinforcement Studying (J-IRL). These variations lead to the identical worth hole bounds as within the single-agent setting.
Multi-agent Aggregation of Losses to Imitate Cached Specialists (MALICE), is an environment friendly algorithm extending the ALICE algorithm to the multi-agent setting. ALICE is an interactive algorithm that makes use of significance sampling to re-weight the BC loss primarily based on the density ratio between the present learner coverage and that of the professional. It requires full demonstration protection to make sure finite significance weights. ALICE makes use of a no-regret algorithm to study a coverage that minimizes reweighed on-policy error, making certain a linear-in-H sure on the worth hole below a recoverability assumption. MALICE adapts these rules to multi-agent environments, offering a sturdy answer for minimizing the remorse hole.
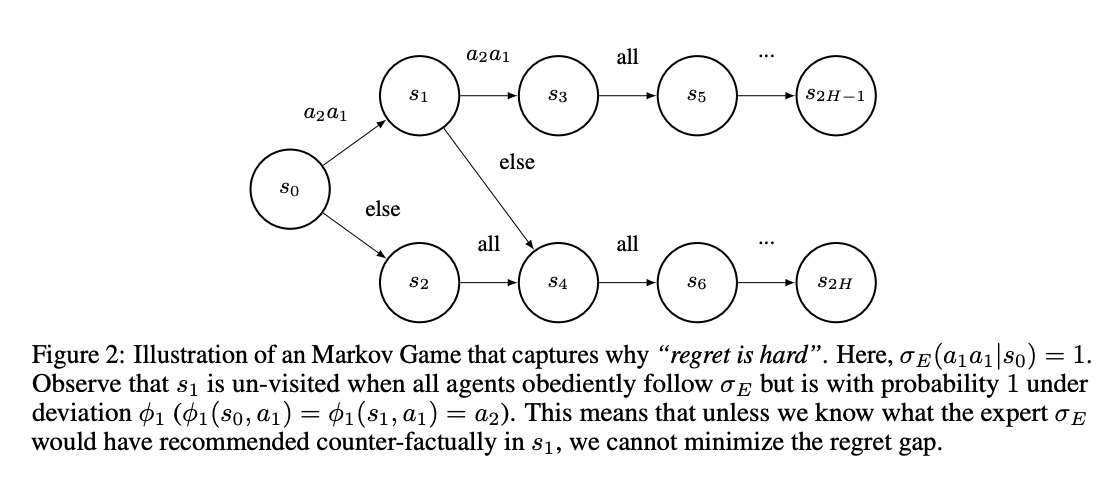
In conclusion, researchers from Carnegie Mellon College have launched another goal for MAIL in Markov Video games known as the remorse hole. For strategic brokers that aren’t mere puppets, one other supply of distribution shift arises from deviations by brokers throughout the inhabitants. This shift can’t be effectively managed via environmental interplay, corresponding to inverse RL. So, it requires estimating the professional’s actions in counterfactual states. Using this perception, the researchers derived two reductions that may reduce the remorse hole below a protection or queryable professional assumption. Future work contains growing and implementing sensible approximations of those idealized algorithms.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here

Sajjad Ansari is a closing yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible functions of AI with a deal with understanding the impression of AI applied sciences and their real-world implications. He goals to articulate advanced AI ideas in a transparent and accessible method.








{kind=link}