

[ad_1]
Basis fashions are large deep-learning fashions which have been pretrained on an infinite quantity of general-purpose, unlabeled knowledge. They are often utilized to quite a lot of duties, like producing pictures or answering buyer questions.
However these fashions, which function the spine for highly effective synthetic intelligence instruments like ChatGPT and DALL-E, can supply up incorrect or deceptive info. In a safety-critical state of affairs, equivalent to a pedestrian approaching a self-driving automotive, these errors might have severe penalties.
To assist stop such errors, researchers from MIT and the MIT-IBM Watson AI Lab developed a way to estimate the reliability of basis fashions earlier than they’re deployed to a particular job.
They do that by contemplating a set of basis fashions which might be barely completely different from each other. Then they use their algorithm to evaluate the consistency of the representations every mannequin learns about the identical check knowledge level. If the representations are constant, it means the mannequin is dependable.
Once they in contrast their approach to state-of-the-art baseline strategies, it was higher at capturing the reliability of basis fashions on quite a lot of downstream classification duties.
Somebody might use this system to resolve if a mannequin ought to be utilized in a sure setting, with out the necessity to check it on a real-world dataset. This may very well be particularly helpful when datasets is probably not accessible as a result of privateness issues, like in well being care settings. As well as, the approach may very well be used to rank fashions based mostly on reliability scores, enabling a person to pick one of the best one for his or her job.
“All fashions could be incorrect, however fashions that know when they’re incorrect are extra helpful. The issue of quantifying uncertainty or reliability is tougher for these basis fashions as a result of their summary representations are troublesome to check. Our technique permits one to quantify how dependable a illustration mannequin is for any given enter knowledge,” says senior creator Navid Azizan, the Esther and Harold E. Edgerton Assistant Professor within the MIT Division of Mechanical Engineering and the Institute for Information, Methods, and Society (IDSS), and a member of the Laboratory for Data and Choice Methods (LIDS).
He’s joined on a paper in regards to the work by lead creator Younger-Jin Park, a LIDS graduate pupil; Hao Wang, a analysis scientist on the MIT-IBM Watson AI Lab; and Shervin Ardeshir, a senior analysis scientist at Netflix. The paper can be offered on the Convention on Uncertainty in Synthetic Intelligence.
Measuring consensus
Conventional machine-learning fashions are educated to carry out a particular job. These fashions sometimes make a concrete prediction based mostly on an enter. As an example, the mannequin may let you know whether or not a sure picture incorporates a cat or a canine. On this case, assessing reliability may very well be a matter of trying on the ultimate prediction to see if the mannequin is true.
However basis fashions are completely different. The mannequin is pretrained utilizing normal knowledge, in a setting the place its creators don’t know all downstream duties will probably be utilized to. Customers adapt it to their particular duties after it has already been educated.
In contrast to conventional machine-learning fashions, basis fashions don’t give concrete outputs like “cat” or “canine” labels. As an alternative, they generate an summary illustration based mostly on an enter knowledge level.
To evaluate the reliability of a basis mannequin, the researchers used an ensemble strategy by coaching a number of fashions which share many properties however are barely completely different from each other.
“Our concept is like measuring the consensus. If all these basis fashions are giving constant representations for any knowledge in our dataset, then we will say this mannequin is dependable,” Park says.
However they bumped into an issue: How might they examine summary representations?
“These fashions simply output a vector, comprised of some numbers, so we will’t examine them simply,” he provides.
They solved this downside utilizing an concept known as neighborhood consistency.
For his or her strategy, the researchers put together a set of dependable reference factors to check on the ensemble of fashions. Then, for every mannequin, they examine the reference factors situated close to that mannequin’s illustration of the check level.
By trying on the consistency of neighboring factors, they will estimate the reliability of the fashions.
Aligning the representations
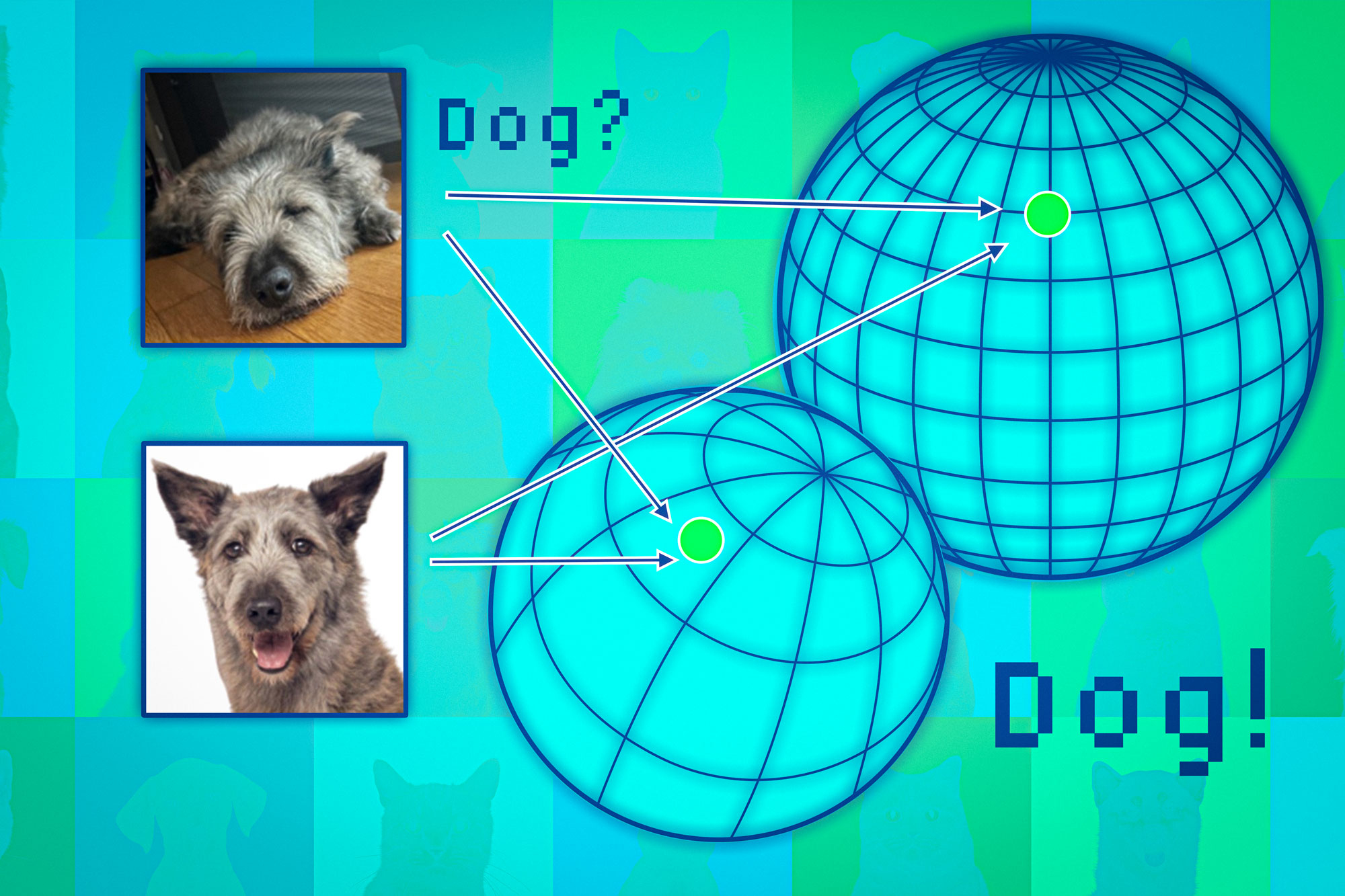
Basis fashions map knowledge factors to what’s referred to as a illustration house. A technique to consider this house is as a sphere. Every mannequin maps related knowledge factors to the identical a part of its sphere, so pictures of cats go in a single place and pictures of canines go in one other.
However every mannequin would map animals in another way in its personal sphere, so whereas cats could also be grouped close to the South Pole of 1 sphere, one other mannequin might map cats someplace within the Northern Hemisphere.
The researchers use the neighboring factors like anchors to align these spheres to allow them to make the representations comparable. If an information level’s neighbors are constant throughout a number of representations, then one ought to be assured in regards to the reliability of the mannequin’s output for that time.
Once they examined this strategy on a variety of classification duties, they discovered that it was way more constant than baselines. Plus, it wasn’t tripped up by difficult check factors that brought on different strategies to fail.
Furthermore, their strategy can be utilized to evaluate reliability for any enter knowledge, so one might consider how properly a mannequin works for a selected sort of particular person, equivalent to a affected person with sure traits.
“Even when the fashions all have common efficiency general, from a person perspective, you’d desire the one which works greatest for that particular person,” Wang says.
Nonetheless, one limitation comes from the truth that they have to prepare an ensemble of basis fashions, which is computationally costly. Sooner or later, they plan to search out extra environment friendly methods to construct a number of fashions, maybe through the use of small perturbations of a single mannequin.
“With the present pattern of utilizing foundational fashions for his or her embeddings to help numerous downstream duties — from fine-tuning to retrieval augmented era — the subject of quantifying uncertainty on the illustration degree is more and more essential, however difficult, as embeddings on their very own don’t have any grounding. What issues as an alternative is how embeddings of various inputs are associated to at least one one other, an concept that this work neatly captures by way of the proposed neighborhood consistency rating,” says Marco Pavone, an affiliate professor within the Division of Aeronautics and Astronautics at Stanford College, who was not concerned with this work. “It is a promising step in direction of top quality uncertainty quantifications for embedding fashions, and I’m excited to see future extensions which might function with out requiring model-ensembling to actually allow this strategy to scale to foundation-size fashions.”
This work is funded, partially, by the MIT-IBM Watson AI Lab, MathWorks, and Amazon.
[ad_2]
Source link


