

[ad_1]
Developments in pure language processing have drastically enhanced the capabilities of language fashions, making them important instruments for varied purposes, together with digital assistants, automated content material creation, and information processing. As these fashions turn out to be extra refined, guaranteeing they generate protected and moral outputs turns into more and more vital. Language fashions, by design, can sometimes produce dangerous or inappropriate content material, posing important dangers when deployed in real-world settings. This has led to rising concern over their security, significantly when dealing with delicate or probably dangerous queries. Making certain these fashions are useful and innocent stays a key problem for researchers.
One of many major points on this space is stopping language fashions from producing unsafe textual content. Whereas strategies like fine-tuning on protected datasets have been developed to deal with this downside, they don’t seem to be foolproof. Fashions can nonetheless be weak to adversarial inputs or fail to acknowledge refined however dangerous outputs. Moreover, as soon as a mannequin begins producing unsafe textual content, it tends to proceed in the identical vein, needing extra means to appropriate itself. This incapacity to get well from unsafe generations creates a persistent downside, as dangerous content material, as soon as generated, typically spirals with out a built-in mechanism to reverse course. Thus, the problem lies in stopping unsafe outputs and creating a way for correcting or undoing them after they happen.
Present strategies for addressing security issues in language fashions primarily concentrate on prevention. Strategies comparable to Supervised Nice-Tuning (SFT) and Reinforcement Studying from Human Suggestions (RLHF) are generally used to cut back the probability of unsafe outputs. These strategies contain coaching the mannequin on examples of protected responses, guiding it to favor moral and acceptable outputs over dangerous ones. Nonetheless, regardless of these developments, fashions skilled with these strategies can nonetheless be tricked into producing unsafe textual content by refined adversarial assaults. There’s additionally a distinguished hole in present strategies: they lack a mechanism that permits the mannequin to backtrack or “reset” when it generates inappropriate content material, limiting their means to deal with problematic instances successfully.

Researchers from Meta AI have launched a method known as “backtracking” to deal with this hole. This methodology offers language fashions the flexibility to undo unsafe outputs by using a particular [RESET] token. The introduction of this token permits the mannequin to discard beforehand generated unsafe content material and start a brand new era from a safer level. This backtracking mechanism may be integrated into present coaching frameworks, comparable to SFT or Direct Desire Optimization (DPO), enhancing the mannequin’s means to detect and get well from unsafe outputs. In contrast to conventional prevention-based strategies, backtracking focuses on correction, enabling the mannequin to regulate its habits in actual time.
The backtracking method permits the language mannequin to watch its output and acknowledge when it begins to generate unsafe content material. When this occurs, the mannequin emits a [RESET] token, which indicators it to discard the hazardous portion of the textual content and restart from a protected place. This methodology is progressive in its means to forestall a cascade of dangerous content material and its adaptability. The researchers skilled their fashions utilizing SFT and DPO strategies, guaranteeing that backtracking might be utilized throughout varied architectures and fashions. Incorporating this into normal language mannequin coaching supplies a seamless method for fashions to self-correct through the era course of with out requiring guide intervention.
The efficiency of the backtracking methodology was examined extensively, with spectacular outcomes. In evaluations, the Llama-3-8B mannequin skilled with backtracking demonstrated a major security enchancment, decreasing the speed of unsafe outputs from 6.1% to only 1.5%. Equally, the Gemma-2-2B mannequin diminished unsafe output era from 10.6% to six.1%. Notably, these security enhancements didn’t come at the price of the mannequin’s usefulness. When it comes to helpfulness, the fashions maintained their utility in non-safety-related duties. The researchers additionally evaluated the backtracking methodology in opposition to a number of adversarial assaults, together with gradient-guided search and mutation-based assaults, discovering that fashions geared up with backtracking had been persistently extra resistant to those assaults than baseline fashions. For instance, the Llama-3-8B mannequin exhibited over a 70% discount in general security violations, proving that backtracking can dramatically enhance mannequin security even underneath difficult situations.
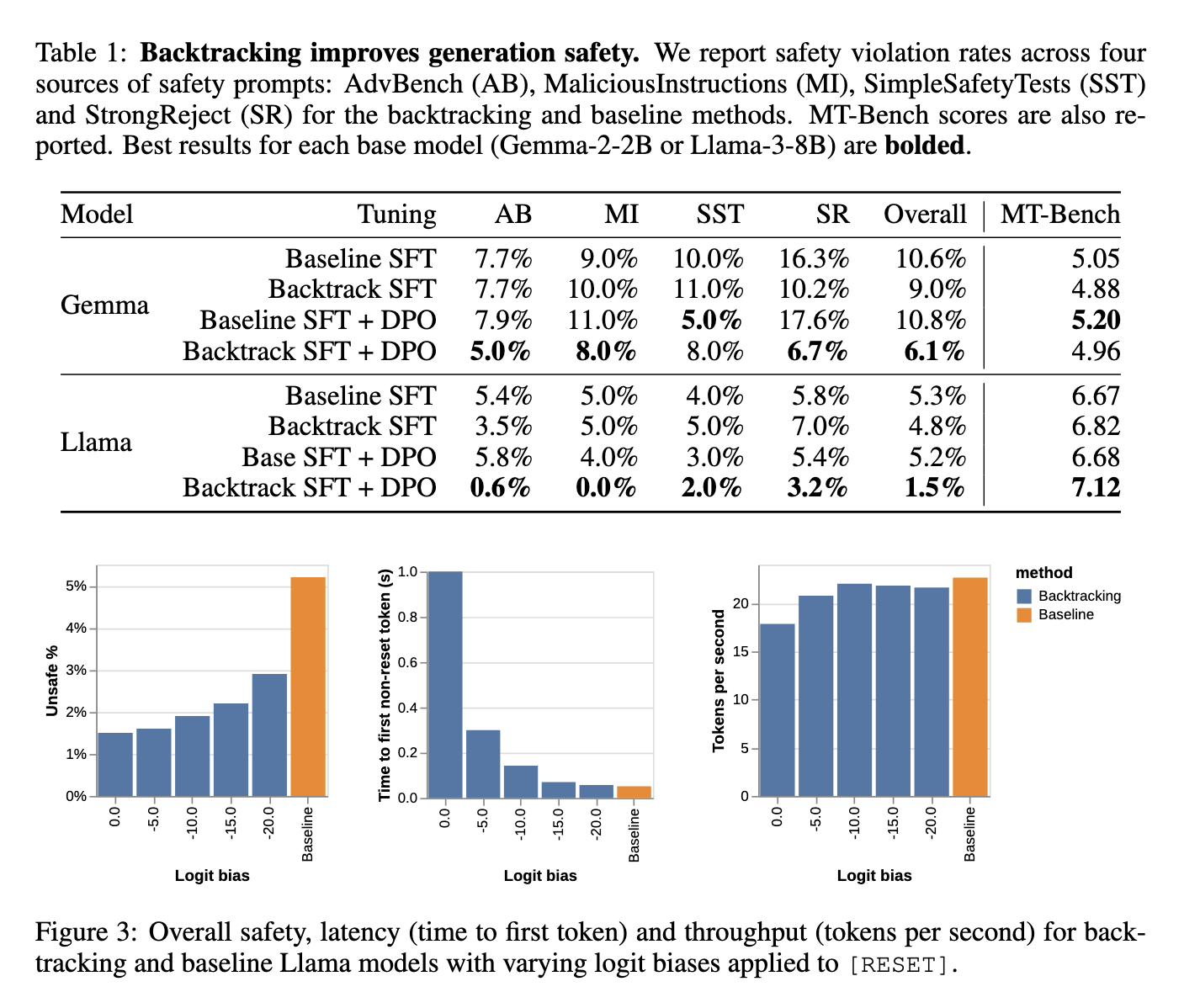
Furthermore, backtracking confirmed appreciable resilience in efficiency effectivity. Though incorporating backtracking added some latency to the era course of—because of the have to discard and regenerate content material—the affect on the general era pace was minimal. Researchers found that adjusting logit bias might additional reduce the trade-off between security and effectivity, permitting for fine-tuning of the tactic’s affect on efficiency. They reported that making use of a small logit bias might protect the mannequin’s era effectivity whereas sustaining a excessive diploma of security. These findings spotlight that the tactic successfully balances security and efficiency, making it a sensible addition to real-world language fashions.
In conclusion, the backtracking methodology provides a novel answer to the issue of unsafe language mannequin generations. Enabling fashions to discard unsafe outputs and generate new, safer responses addresses a vital hole in present security strategies. The outcomes of the examine carried out by researchers from Meta and Carnegie Mellon College show that backtracking can considerably enhance the protection of language fashions with out compromising their utility. This methodology represents a promising step ahead within the ongoing effort to make sure that language fashions are useful and innocent when utilized in sensible purposes.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 50k+ ML SubReddit.
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.
[ad_2]
Source link


