

Recurrent neural networks (RNNs) have been foundational in machine studying for addressing varied sequence-based issues, together with time sequence forecasting and pure language processing. RNNs are designed to deal with sequences of various lengths by sustaining an inside state that captures info throughout time steps. Nonetheless, these fashions typically wrestle with vanishing and exploding gradient points, which scale back their effectiveness for longer sequences. To deal with this limitation, varied architectural developments have been developed over time, enhancing the power of RNNs to seize long-term dependencies and carry out extra complicated sequence-based duties.
A big problem in sequence modeling is the computational inefficiency of current fashions, significantly for lengthy sequences. Transformers have emerged as a dominant structure, reaching state-of-the-art leads to quite a few purposes corresponding to language modeling and translation. Nonetheless, their quadratic complexity regarding sequence size renders them resource-intensive and impractical for a lot of purposes with longer sequences or restricted computational sources. This has led to a renewed curiosity in fashions that may steadiness efficiency and effectivity, guaranteeing scalability with out compromising on accuracy.
A number of present strategies have been proposed to deal with this downside, corresponding to state-space fashions like Mamba, which make the most of input-dependent transitions to effectively handle sequences. Different strategies, like linear consideration fashions, optimize coaching by lowering the computation required for longer sequences. Regardless of reaching efficiency similar to transformers, these strategies typically contain complicated algorithms and require specialised strategies for environment friendly implementation. Furthermore, attention-based mechanisms like Aaren and S4 have launched revolutionary methods to deal with the inefficiencies, however they nonetheless face limitations, corresponding to elevated reminiscence utilization and complexity in implementation.
The researchers at Borealis AI and Mila—Université de Montréal have reexamined conventional RNN architectures, particularly the Lengthy Quick-Time period Reminiscence (LSTM) and Gated Recurrent Unit (GRU) fashions. They launched simplified, minimal variations of those fashions, named minLSTM and minGRU, to deal with the scalability points confronted by their conventional counterparts. By eradicating hidden state dependencies, the minimal variations not require backpropagation via time (BPTT) and may be educated in parallel, considerably bettering effectivity. This breakthrough allows these minimal RNNs to deal with longer sequences with decreased computational prices, making them aggressive with the newest sequence fashions.
The proposed minimal LSTM and GRU fashions get rid of varied gating mechanisms which can be computationally costly and pointless for a lot of sequence duties. By simplifying the structure and guaranteeing the outputs are time-independent in scale, the researchers have been capable of create fashions that use as much as 33% fewer parameters than conventional RNNs. Additional, the modified structure permits for parallel coaching, making these minimal fashions as much as 175 occasions quicker than normal LSTMs and GRUs when dealing with sequences of size 512. This enchancment in coaching pace is essential for scaling up the fashions for real-world purposes that require dealing with lengthy sequences, corresponding to textual content technology and language modeling.
By way of efficiency and outcomes, the minimal RNNs demonstrated substantial positive factors in coaching time and effectivity. For instance, on a T4 GPU, the minGRU mannequin achieved a 175x speedup in coaching time in comparison with the standard GRU for a sequence size of 512, whereas minLSTM confirmed a 235x enchancment. For even longer sequences of size 4096, the speedup was much more pronounced, with minGRU and minLSTM reaching speedups of 1324x and 1361x, respectively. These enhancements make the minimal RNNs extremely appropriate for purposes requiring quick and environment friendly coaching. The fashions additionally carried out competitively with fashionable architectures like Mamba in empirical exams, displaying that the simplified RNNs can obtain related and even superior outcomes with a lot decrease computational overhead.
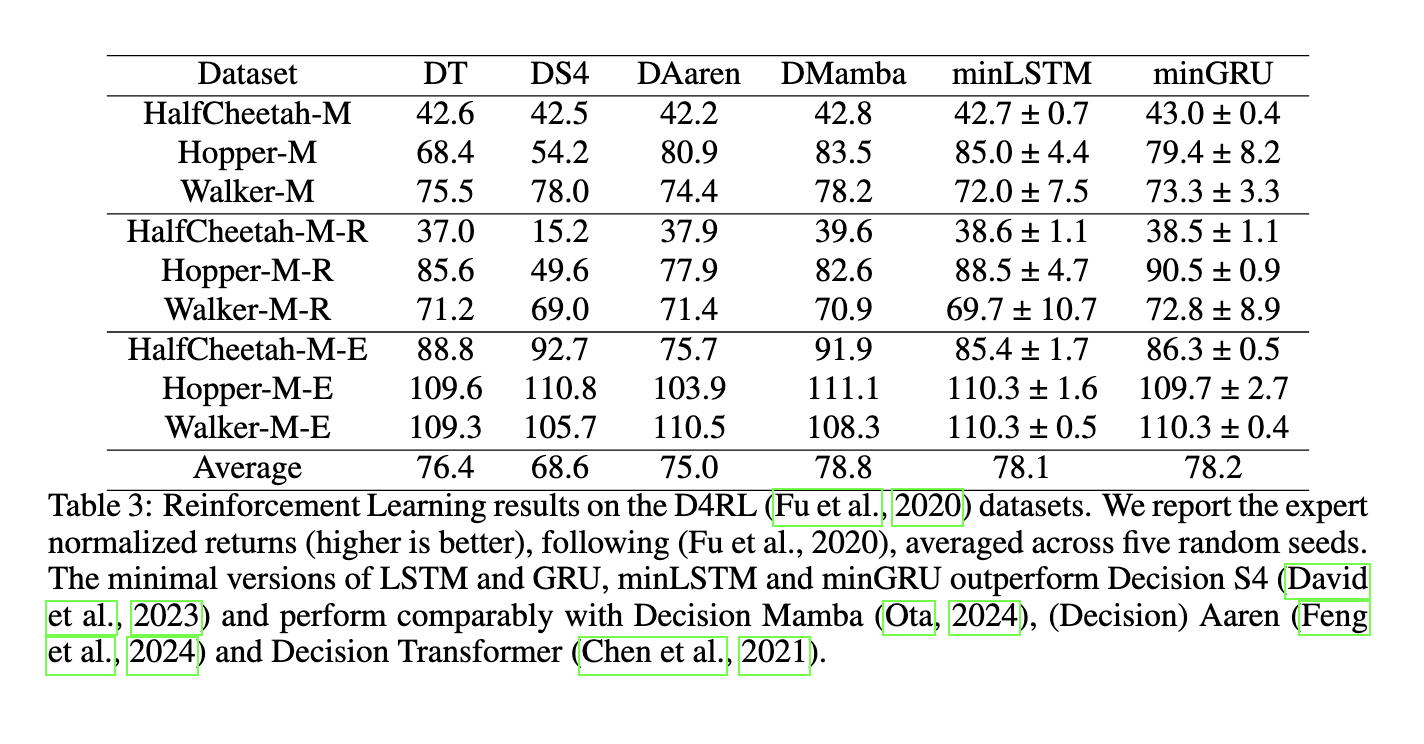
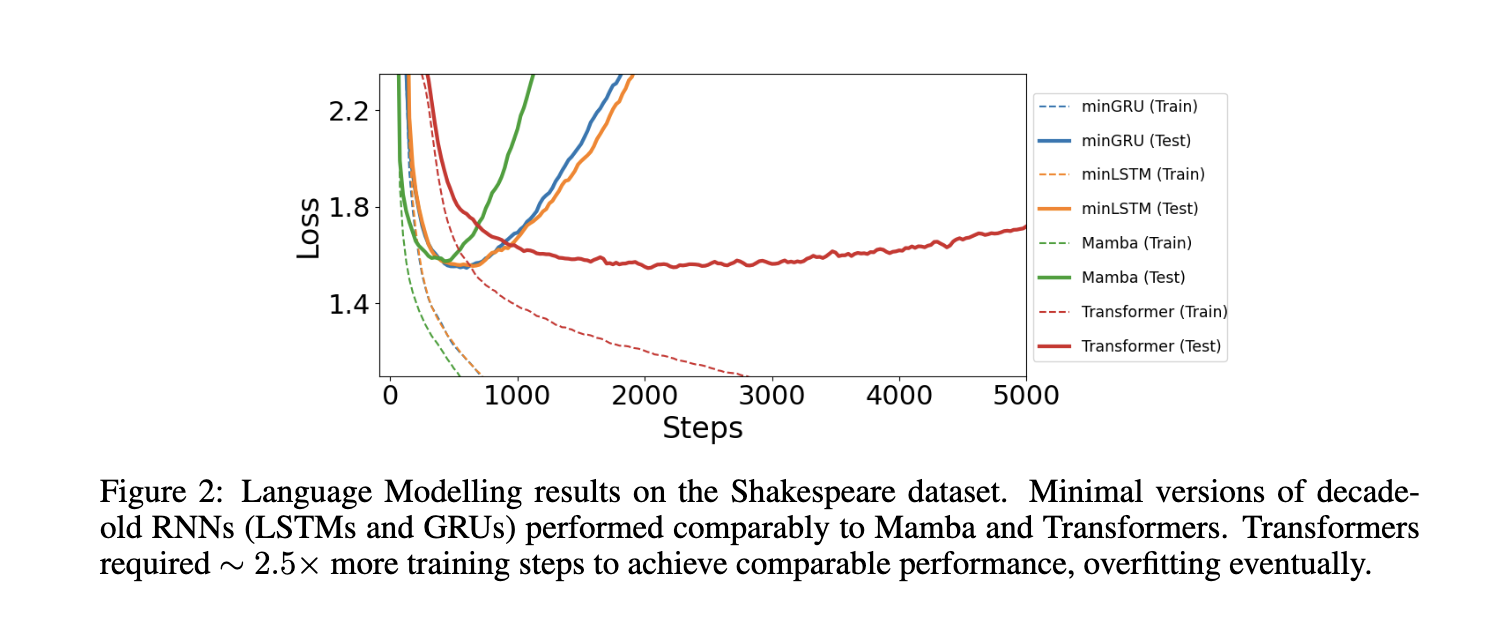
The researchers additional examined the minimal fashions on reinforcement studying duties and language modeling. Within the reinforcement studying experiments, the minimal fashions outperformed current strategies corresponding to Choice S4 and carried out comparably with Mamba and Choice Transformer. For instance, on the Hopper-Medium dataset, the minLSTM mannequin achieved a efficiency rating of 85.0, whereas the minGRU scored 79.4, indicating sturdy outcomes throughout various ranges of knowledge high quality. Equally, in language modeling duties, minGRU and minLSTM achieved cross-entropy losses similar to transformer-based fashions, with minGRU reaching a lack of 1.548 and minLSTM reaching a lack of 1.555 on the Shakespeare dataset. These outcomes spotlight the effectivity and robustness of the minimal fashions in numerous sequence-based purposes.
In conclusion, the analysis group’s introduction of minimal LSTMs and GRUs addresses the computational inefficiencies of conventional RNNs whereas sustaining sturdy empirical efficiency. By simplifying the fashions and leveraging parallel coaching, the minimal variations supply a viable different to extra complicated fashionable architectures. The findings counsel that with some modifications, conventional RNNs can nonetheless be efficient for lengthy sequence modeling duties, making these minimal fashions a promising answer for future analysis and purposes within the discipline.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our publication.. Don’t Neglect to hitch our 50k+ ML SubReddit
Focused on selling your organization, product, service, or occasion to over 1 Million AI builders and researchers? Let’s collaborate!
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.




 | by Sandi Besen | Dec, 2024")



