

[ad_1]
The Pores and skin Situation Picture Community (SCIN) dataset provides a various and consultant assortment of pores and skin situation pictures, bridging essential gaps for AI improvement, medical analysis, and equitable healthcare instruments.
Well being datasets play an important function in analysis and medical schooling, however it may be difficult to create a dataset that represents the true world. For instance, dermatology circumstances are various of their look and severity and manifest in a different way throughout pores and skin tones. But, present dermatology picture datasets usually lack illustration of on a regular basis circumstances (like rashes, allergic reactions and infections) and skew in the direction of lighter pores and skin tones. Moreover, race and ethnicity info is often lacking, hindering our means to evaluate disparities or create options.
To handle these limitations, we’re releasing the Pores and skin Situation Picture Community (SCIN) dataset in collaboration with physicians at Stanford Drugs. We designed SCIN to replicate the broad vary of issues that folks seek for on-line, supplementing the varieties of circumstances usually present in scientific datasets. It accommodates pictures throughout varied pores and skin tones and physique components, serving to to make sure that future AI instruments work successfully for all. We have made the SCIN dataset freely out there as an open-access useful resource for researchers, educators, and builders, and have taken cautious steps to guard contributor privateness.
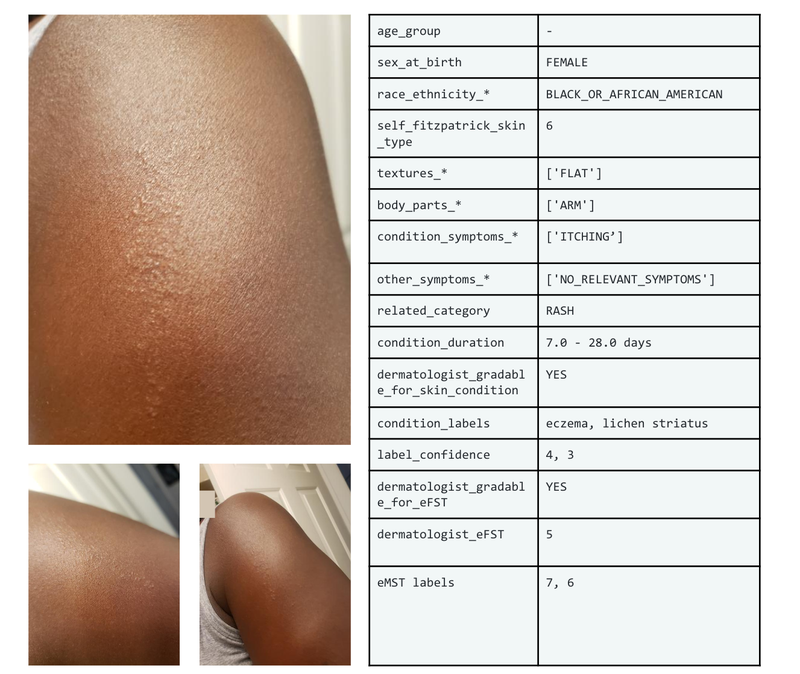
Instance set of pictures and metadata from the SCIN dataset.
Dataset composition
The SCIN dataset at present accommodates over 10,000 pictures of pores and skin, nail, or hair circumstances, straight contributed by people experiencing them. All contributions have been made voluntarily with knowledgeable consent by people within the US, underneath an institutional-review board permitted examine. To supply context for retrospective dermatologist labeling, contributors have been requested to take pictures each close-up and from barely additional away. They got the choice to self-report demographic info and tanning propensity (self-reported Fitzpatrick Pores and skin Sort, i.e., sFST), and to explain the feel, length and signs associated to their concern.
One to 3 dermatologists labeled every contribution with as much as 5 dermatology circumstances, together with a confidence rating for every label. The SCIN dataset accommodates these particular person labels, in addition to an aggregated and weighted differential prognosis derived from them that might be helpful for mannequin testing or coaching. These labels have been assigned retrospectively and will not be equal to a scientific prognosis, however they permit us to check the distribution of dermatology circumstances within the SCIN dataset with present datasets.
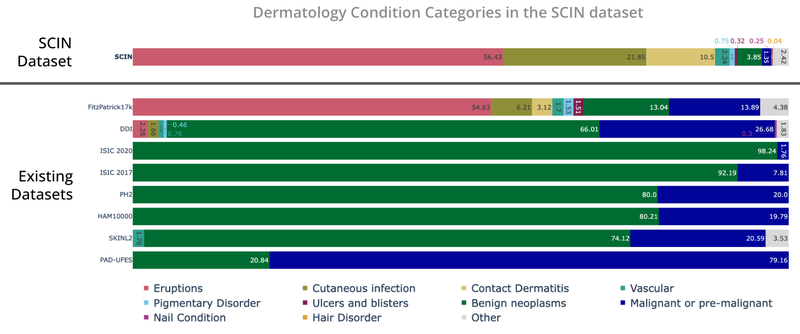
The SCIN dataset accommodates largely allergic, inflammatory and infectious circumstances whereas datasets from scientific sources give attention to benign and malignant neoplasms.
Whereas many present dermatology datasets give attention to malignant and benign tumors and are supposed to help with pores and skin most cancers prognosis, the SCIN dataset consists largely of widespread allergic, inflammatory, and infectious circumstances. The vast majority of pictures within the SCIN dataset present early-stage issues — greater than half arose lower than every week earlier than the picture, and 30% arose lower than a day earlier than the picture was taken. Circumstances inside this time window are seldom seen inside the well being system and subsequently are underrepresented in present dermatology datasets.
We additionally obtained dermatologist estimates of Fitzpatrick Pores and skin Sort (estimated FST or eFST) and layperson labeler estimates of Monk Pores and skin Tone (eMST) for the photographs. This allowed comparability of the pores and skin situation and pores and skin kind distributions to these in present dermatology datasets. Though we didn’t selectively goal any pores and skin sorts or pores and skin tones, the SCIN dataset has a balanced Fitzpatrick pores and skin kind distribution (with extra of Varieties 3, 4, 5, and 6) in comparison with comparable datasets from scientific sources.
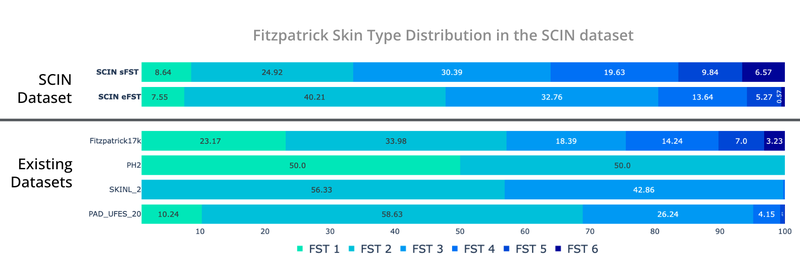
Self-reported and dermatologist-estimated Fitzpatrick Pores and skin Sort distribution within the SCIN dataset in contrast with present un-enriched dermatology datasets (Fitzpatrick17k, PH², SKINL2, and PAD-UFES-20).
The Fitzpatrick Pores and skin Sort scale was initially developed as a photo-typing scale to measure the response of pores and skin sorts to UV radiation, and it’s broadly utilized in dermatology analysis. The Monk Pores and skin Tone scale is a more moderen 10-shade scale that measures pores and skin tone fairly than pores and skin phototype, capturing extra nuanced variations between the darker pores and skin tones. Whereas neither scale was supposed for retrospective estimation utilizing pictures, the inclusion of those labels is meant to allow future analysis into pores and skin kind and tone illustration in dermatology. For instance, the SCIN dataset offers an preliminary benchmark for the distribution of those pores and skin sorts and tones within the US inhabitants.
The SCIN dataset has a excessive illustration of girls and youthful people, doubtless reflecting a mixture of things. These may embody variations in pores and skin situation incidence, propensity to hunt well being info on-line, and variations in willingness to contribute to analysis throughout demographics.
Crowdsourcing technique
To create the SCIN dataset, we used a novel crowdsourcing technique, which we describe within the accompanying analysis paper co-authored with investigators at Stanford Drugs. This strategy empowers people to play an lively function in healthcare analysis. It permits us to succeed in individuals at earlier phases of their well being issues, probably earlier than they search formal care. Crucially, this technique makes use of ads on internet search consequence pages — the place to begin for many individuals’s well being journey — to attach with individuals.
Our outcomes exhibit that crowdsourcing can yield a high-quality dataset with a low spam charge. Over 97.5% of contributions have been real pictures of pores and skin circumstances. After performing additional filtering steps to exclude pictures that have been out of scope for the SCIN dataset and to take away duplicates, we have been capable of launch almost 90% of the contributions acquired over the 8-month examine interval. Most pictures have been sharp and well-exposed. Roughly half of the contributions embody self-reported demographics, and 80% comprise self-reported info referring to the pores and skin situation, resembling texture, length, or different signs. We discovered that dermatologists’ means to retrospectively assign a differential prognosis depended extra on the supply of self-reported info than on picture high quality.
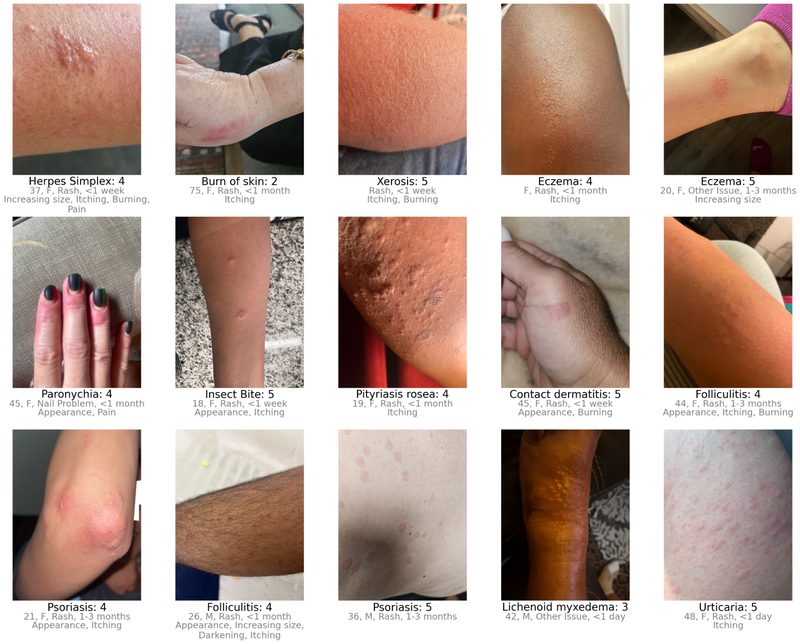
Dermatologist confidence of their labels (scale from 1-5) relied on the supply of self-reported demographic and symptom info.
Whereas good picture de-identification can by no means be assured, defending the privateness of people who contributed their pictures was a prime precedence when creating the SCIN dataset. By means of knowledgeable consent, contributors have been made conscious of potential re-identification dangers and suggested to keep away from importing pictures with figuring out options. Submit-submission privateness safety measures included handbook redaction or cropping to exclude probably figuring out areas, reverse picture searches to exclude publicly out there copies and metadata removing or aggregation. The SCIN Knowledge Use License prohibits makes an attempt to re-identify contributors.
We hope the SCIN dataset can be a useful useful resource for these working to advance inclusive dermatology analysis, schooling, and AI instrument improvement. By demonstrating a substitute for conventional dataset creation strategies, SCIN paves the best way for extra consultant datasets in areas the place self-reported information or retrospective labeling is possible.
Acknowledgements
We’re grateful to all our co-authors Abbi Ward, Jimmy Li, Julie Wang, Sriram Lakshminarasimhan, Ashley Carrick, Bilson Campana, Jay Hartford, Pradeep Kumar S, Tiya Tiyasirisokchai, Sunny Virmani, Renee Wong, Yossi Matias, Greg S. Corrado, Dale R. Webster, Daybreak Siegel (Stanford Drugs), Steven Lin (Stanford Drugs), Justin Ko (Stanford Drugs), Alan Karthikesalingam and Christopher Semturs. We additionally thank Yetunde Ibitoye, Sami Lachgar, Lisa Lehmann, Javier Perez, Margaret Ann Smith (Stanford Drugs), Rachelle Sico, Amit Talreja, Annisah Um’rani and Wayne Westerlind for his or her important contributions to this work. Lastly, we’re grateful to Heather Cole-Lewis, Naama Hammel, Ivor Horn, Michael Howell, Yun Liu, and Eric Teasley for his or her insightful feedback on the examine design and manuscript.
[ad_2]
Source link


