

[ad_1]
Creating songs from textual content is troublesome as a result of it entails producing vocals and instrumental music collectively. Songs are distinctive as they mix lyrics and melodies to precise feelings, making the method extra complicated than producing speech or instrumental music alone. The problem is intensified by the inadequate availability of high quality open-source information, which restrains analysis and improvement within the space. Some approaches incorporate a number of steps, with vocals generated within the first place and the accompaniment generated individually. Such a way hinders the method of coaching and prediction and lessens the management of the ultimate track. A serious problem is whether or not a single-step mannequin can simplify this course of whereas sustaining high quality and suppleness.
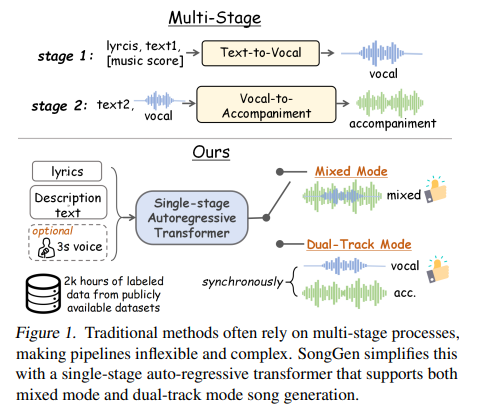
Presently, text-to-music technology fashions use descriptive textual content to create music, however most strategies battle to generate reasonable vocals. Transformer-based fashions course of audio as discrete tokens and diffusion fashions produce high-quality instrumental music, however each approaches face points with vocal technology. Track technology, which mixes vocals with instrumental music, depends on multi-stage strategies like Jukebox, Melodist, and MelodyLM. These strategies produce vocals and accompaniment independently, so the method is sophisticated and exhausting to handle. And not using a widespread technique, flexibility is restricted, and inefficiencies in coaching and inference are enhanced.
To generate a track from textual content descriptions, lyrics, and non-compulsory reference voice, researchers proposed SongGen, an auto-regressive transformer decoder with an built-in neural audio codec. The mannequin predicts audio token sequences, that are synthesized into songs. SongGen helps two technology modes: Blended Mode and Twin-Monitor Mode. In Blended Mode, X-Codec encodes uncooked audio into discrete tokens, with coaching loss emphasizing earlier codebooks to enhance vocal readability. A variant, Blended Professional, introduces an auxiliary loss for vocals to boost their high quality. Twin-Monitor Mode individually generates vocals and accompaniment, synchronizing them by means of Parallel or Interleaving patterns. Parallel mode aligns tokens frame-by-frame, whereas Interleaving mode enhances interplay between vocals and accompaniment throughout layers.
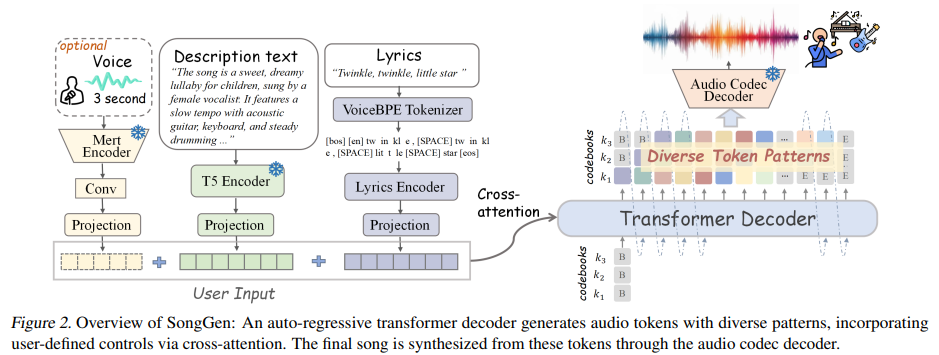
For conditioning, lyrics are processed utilizing a VoiceBPE tokenizer, voice options are extracted by way of a frozen MERT encoder, and textual content attributes are encoded utilizing FLAN-T5. These embeddings information track technology by way of cross-attention. Because of the lack of public text-to-song datasets, an automatic pipeline processes 8,000 hours of audio from a number of sources, guaranteeing high quality information by means of filtering methods.
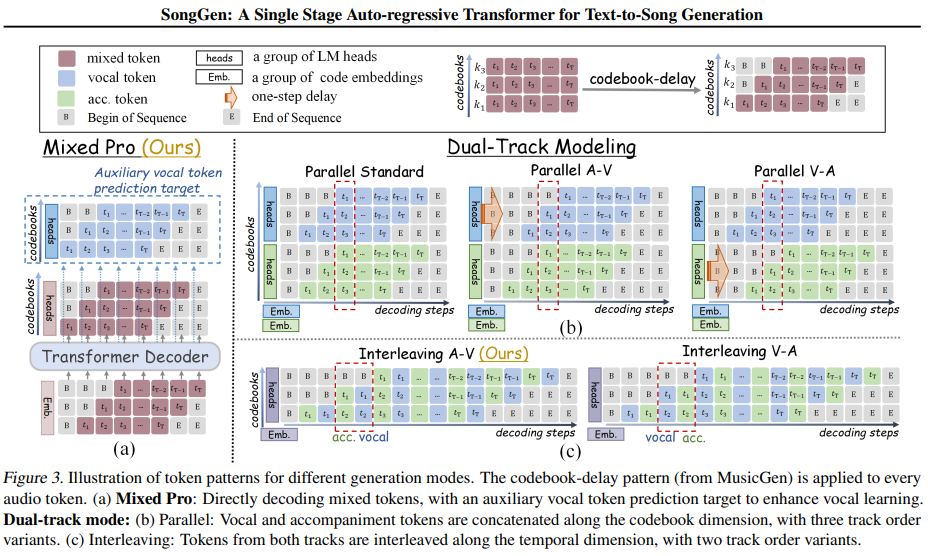
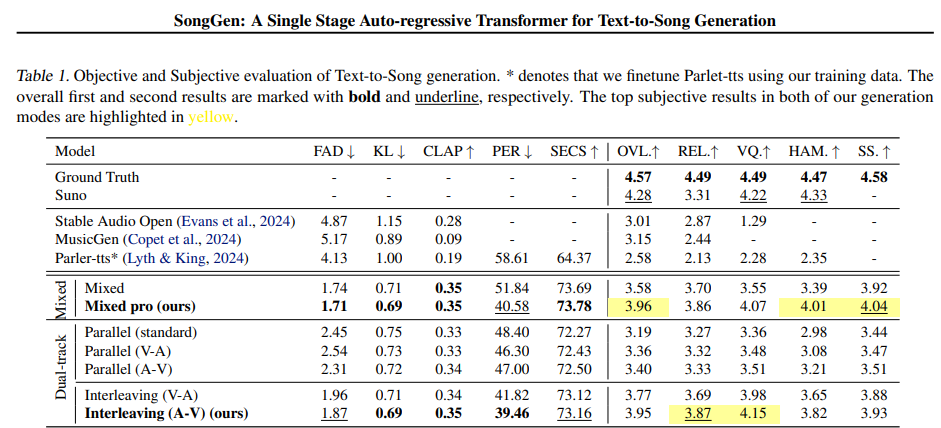
Researchers evaluated SongGen with Secure Audio Open, MusicGen, Parler-tts, and Suno for text-to-song technology. MusicGen produced solely instrumental music, whereas Secure Audio Open generated unclear vocal sounds, and fine-tuning Parler-tts for singing proved ineffective. Regardless of utilizing solely 2,000 hours of labeled information, SongGen outperformed these fashions in textual content relevance and vocal management. Amongst its modes, the “Blended Professional” method enhanced vocal high quality (VQ) and phoneme error charge (PER), whereas the “Interleaving (A-V)” dual-track technique excelled in vocal high quality however had barely decrease concord (HAM). Consideration evaluation revealed that SongGen successfully captured musical buildings. The mannequin maintained coherence with minor efficiency drops even with out a reference voice. Ablation research confirmed that high-quality fine-tuning (HQFT), curriculum studying (CL), and VoiceBPE-based lyric tokenization improved stability and accuracy.
In conclusion, the proposed mannequin simplified text-to-song technology by introducing a single-stage, auto-regressive transformer that supported combined and dual-track modes, demonstrating robust efficiency. Its open-source function made it extra accessible in order that novices and specialists may produce music with precision management over voice and instrument parts. Nevertheless, the mannequin’s functionality to imitate voices is ethically problematic, calling for cover from abuse. As a foundational work in controllable text-to-song technology, SongGen can function a baseline for future analysis, guiding enhancements in audio high quality, lyric alignment, and expressive singing synthesis whereas addressing moral and authorized challenges.
Try the Technical Particulars and GitHub Web page. All credit score for this analysis goes to the researchers of this challenge. Additionally, be happy to observe us on Twitter and don’t overlook to affix our 80k+ ML SubReddit.
🚨 Really useful Learn- LG AI Analysis Releases NEXUS: An Superior System Integrating Agent AI System and Knowledge Compliance Requirements to Handle Authorized Considerations in AI Datasets
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Expertise, Kharagpur. He’s a Knowledge Science and Machine studying fanatic who desires to combine these main applied sciences into the agricultural area and resolve challenges.
[ad_2]
Source link


