

The event of language modeling focuses on creating synthetic intelligence techniques that may course of and generate textual content with human-like fluency. These fashions play important roles in machine translation, content material era, and conversational AI purposes. They depend on in depth datasets and sophisticated coaching algorithms to study linguistic patterns, enabling them to know context, reply to queries, and create coherent textual content. The fast evolution on this discipline highlights the rising significance of open-source contributions, which intention to democratize entry to highly effective AI techniques.
A persistent situation within the discipline has been the dominance of proprietary fashions, which frequently outperform open-source techniques as a result of their in depth assets and optimized coaching pipelines. Proprietary techniques incessantly leverage large datasets, compute energy, and superior proprietary methodologies, making a efficiency hole that open fashions need assistance to shut. This disparity limits accessibility and innovation in AI, as solely well-funded organizations can afford to develop such cutting-edge know-how.
Whereas commendable, present open-source strategies nonetheless want to completely deal with the challenges of scalability, coaching stability, and mannequin efficiency. Many fashions are both partially open, offering solely restricted datasets or methodologies, or absolutely open however want a aggressive edge over their proprietary counterparts. Nonetheless, latest developments are paving the way in which for a brand new era of absolutely open and aggressive fashions by way of efficiency.
The Allen Institute for AI analysis crew launched OLMo 2, a groundbreaking household of open-source language fashions. These fashions, out there in 7 billion (7B) and 13 billion (13B) parameter configurations, have been educated on as much as 5 trillion tokens utilizing state-of-the-art methods. By refining coaching stability, adopting staged coaching processes, and incorporating numerous datasets, the researchers bridged the efficiency hole with proprietary techniques like Llama 3.1. OLMo 2 leverages enhancements in layer normalization, rotary positional embeddings, and Z-loss regularization to boost mannequin robustness.
OLMo 2’s coaching employed a curriculum method throughout two phases. Within the first stage, protecting 90% of the pretraining price range, the fashions have been educated on the OLMo-Combine-1124 dataset, comprising 3.9 trillion tokens sourced from varied high-quality repositories like DCLM and Starcoder. The second stage concerned fine-tuning Dolmino-Combine-1124, a curated dataset of 843 billion tokens that includes web-based and domain-specific content material. Methods like mannequin souping, which merges checkpoints to optimize efficiency, have been important in attaining the ultimate variations of the 7B and 13B fashions.
The efficiency of OLMo 2 units new benchmarks within the discipline of open-source language modeling. In comparison with its predecessor, OLMo-0424, OLMo 2 demonstrates a major increase throughout all analysis duties. OLMo 2 7B notably outperforms Llama-3.1 8B, and OLMo 2 13B surpasses Qwen 2.5 7B, regardless of using fewer coaching FLOPs. Analysis utilizing the Open Language Modeling Analysis System (OLMES), a collection of 20 benchmarks, confirmed these features, highlighting strengths in data recall, reasoning, and basic language capabilities.
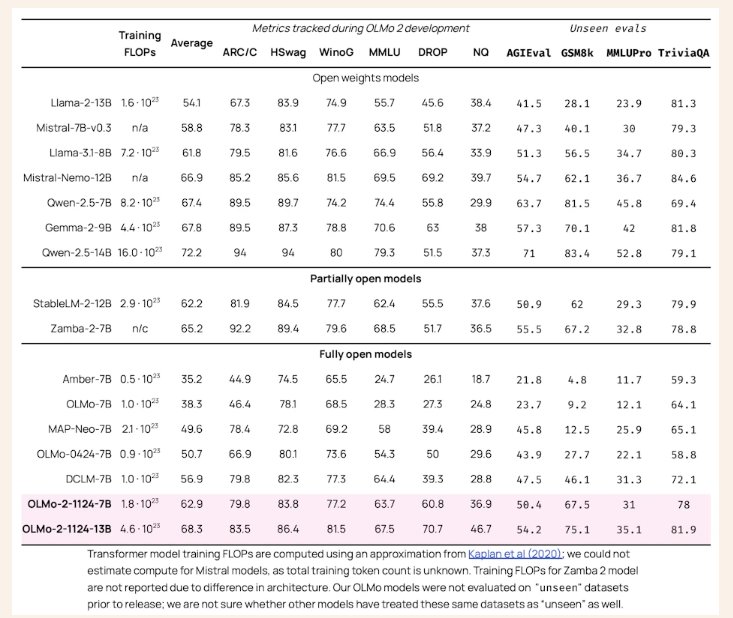
Key takeaways from the analysis embrace the next developments:
Coaching Stability Enhancements: Methods like RMSNorm and studying price annealing lowered loss spikes throughout pretraining, making certain constant mannequin efficiency.
Progressive Staged Coaching: Late pretraining interventions, together with information curriculum changes, allowed for focused enhancement of mannequin capabilities.
Actionable Analysis Framework: The introduction of OLMES supplied structured benchmarks to information mannequin growth and monitor progress successfully.
Publish-Coaching Methodologies: Supervised fine-tuning, choice tuning, and reinforcement studying with verifiable rewards enhanced the fashions’ instruction-following capabilities.
Dataset Range and High quality: Pretraining on datasets like Dolmino-Combine-1124 ensured the fashions might generalize throughout numerous domains.
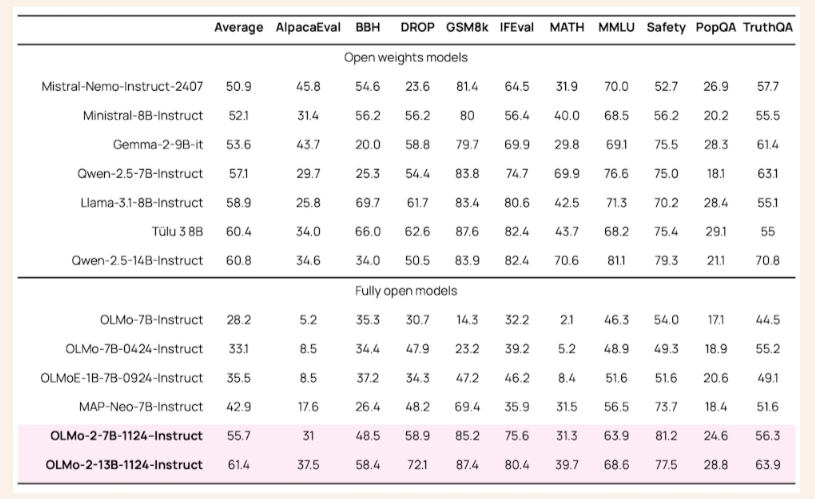

In conclusion, OLMo 2’s achievements signify a shift within the language modeling panorama. By addressing challenges corresponding to coaching stability and analysis transparency, the researchers have set a brand new normal for open-source AI. These fashions shut the hole with proprietary techniques and exhibit the potential of collaborative innovation in advancing synthetic intelligence. The OLMo 2 initiative underscores the transformative energy of open entry to high-performance AI fashions, paving the way in which for extra equitable technological developments.
Take a look at the Fashions on Hugging Face and Particulars. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our publication.. Don’t Overlook to hitch our 55k+ ML SubReddit.
🎙️ 🚨 ‘Analysis of Massive Language Mannequin Vulnerabilities: A Comparative Evaluation of Crimson Teaming Methods’ Learn the Full Report (Promoted)
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.




 | by Sandi Besen | Dec, 2024")



