

[ad_1]
Massive-scale language fashions (LLMs) have superior the sphere of synthetic intelligence as they’re utilized in many functions. Though they’ll virtually completely simulate human language, they have a tendency to lose by way of response range. This limitation is especially problematic in duties requiring creativity, corresponding to artificial information era and storytelling, the place various outputs are important for sustaining relevance and engagement.
One of many main challenges in language mannequin optimization is the discount in response range as a consequence of choice coaching strategies. Put up-training strategies like reinforcement studying from human suggestions (RLHF) and direct choice optimization (DPO) have a tendency to pay attention chance mass on a restricted variety of high-reward responses. This ends in fashions producing repetitive outputs for varied prompts, limiting their adaptability in inventive functions. The decline in range hinders the potential of language fashions to operate successfully in fields that require broad-ranging outputs.

Earlier strategies for choice optimization primarily emphasize aligning fashions with high-quality human preferences. Supervised fine-tuning and RLHF strategies, whereas efficient at bettering mannequin alignment, inadvertently result in response homogenization. Direct Desire Optimization (DPO) selects extremely rewarded responses whereas discarding low-quality ones, reinforcing the tendency for fashions to supply predictable outputs. Makes an attempt to counteract this problem, corresponding to adjusting sampling temperatures or making use of KL divergence regularization, have did not considerably improve range with out compromising output high quality.
Researchers from Meta, New York College, and ETH Zurich have launched Numerous Desire Optimization (DivPO), a novel approach designed to boost response range whereas sustaining top quality. In contrast to conventional optimization strategies prioritizing the highest-rewarded response, DivPO selects choice pairs primarily based on high quality and variety. This ensures that the mannequin generates outputs that aren’t solely human-aligned but in addition various, making them simpler in inventive and data-driven functions.

DivPO operates by sampling a number of responses for a given immediate and scoring them utilizing a reward mannequin. As an alternative of choosing the only highest-rewarded response, probably the most various, high-quality response is chosen as the popular output. Concurrently, the least various response that doesn’t meet the standard threshold is chosen because the rejected output. This contrastive optimization technique permits DivPO to be taught a broader distribution of responses whereas making certain that every output retains a high-quality commonplace. The method incorporates varied range standards, together with mannequin chance, phrase frequency, and an LLM-based range judgment, to evaluate every response’s distinctiveness systematically.
In depth experiments had been performed to validate the effectiveness of DivPO, specializing in structured persona era and open-ended inventive writing duties. The outcomes demonstrated that DivPO considerably elevated range with out sacrificing high quality. In comparison with commonplace choice optimization strategies, DivPO led to a forty five.6% improve in persona attribute range and a 74.6% rise in story range. The experiments additionally confirmed that DivPO prevents fashions from producing a small subset of responses disproportionately, making certain a extra even distribution of generated attributes. A key statement was that fashions skilled utilizing DivPO constantly outperformed baseline fashions in range evaluations whereas sustaining top quality, as assessed by the ArmoRM reward mannequin.
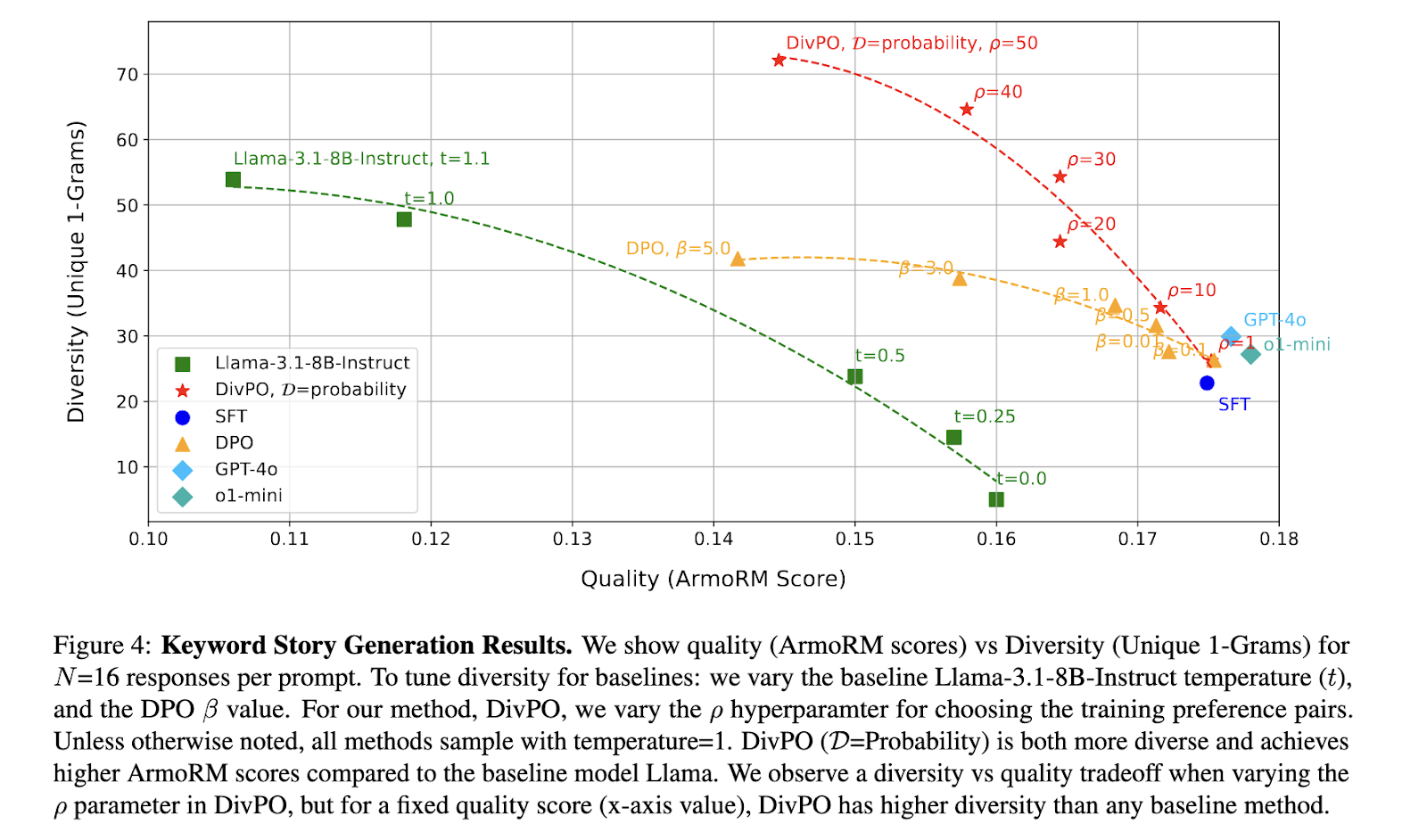
Additional evaluation of persona era revealed that conventional fine-tuned fashions, corresponding to Llama-3.1-8B-Instruct, failed to supply various persona attributes, usually repeating a restricted set of names. DivPO rectified this problem by increasing the generated attribute vary, resulting in a extra balanced and consultant output distribution. The structured persona era process demonstrated that on-line DivPO with phrase frequency standards improved range by 30.07% in comparison with the baseline mannequin whereas sustaining a comparable stage of response high quality. Equally, the keyword-based inventive writing process confirmed a considerable enchancment, with DivPO attaining a 13.6% improve in range and a 39.6% improve in high quality relative to the usual choice optimization fashions.
These findings affirm that choice optimization strategies inherently scale back range, difficult language fashions designed for open-ended duties. DivPO successfully mitigates this problem by incorporating diversity-aware choice standards, enabling language fashions to take care of high-quality responses with out limiting variability. By balancing range with alignment, DivPO enhances the adaptability and utility of LLMs throughout a number of domains, making certain they continue to be helpful for inventive, analytical, and artificial information era functions. The introduction of DivPO marks a major development in choice optimization, providing a sensible resolution to the long-standing drawback of response collapse in language fashions.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to affix our 75k+ ML SubReddit.
🚨 Marktechpost is inviting AI Firms/Startups/Teams to companion for its upcoming AI Magazines on ‘Open Supply AI in Manufacturing’ and ‘Agentic AI’.
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.
[ad_2]
Source link

