

Massive language fashions (LLMs) are developed particularly for math, programming, and common autonomous brokers and require enchancment in reasoning at check time. Varied approaches embody producing reasoning steps in response to some immediate or utilizing sampling and coaching fashions to generate the identical step. Reinforcement studying is extra probably to present self-exploration and the power to study from suggestions; nonetheless, their impression on advanced reasoning has remained restricted. Scaling LLMs at check time remains to be a difficulty as a result of elevated computational efforts don’t essentially translate to higher fashions. Deep reasoning and longer responses can doubtlessly enhance efficiency, but it surely has been difficult to realize this successfully.
Present strategies for bettering language mannequin reasoning deal with imitation studying, the place fashions replicate reasoning steps generated utilizing prompts or rejection sampling. Pretraining on reasoning-related information and fine-tuning with reinforcement studying assist enhance understanding, however they don’t scale properly for advanced reasoning. Put up-training methods like producing question-answer pairs and including verifiers enhance accuracy however rely closely on exterior supervision. Scaling language fashions by extra information and bigger fashions enhances efficiency, however reinforcement learning-based scaling and test-time inference stay ineffective. Repeated sampling will increase computational prices with out enhancing reasoning skill, making present methods inefficient for deeper reasoning and long-form responses.
To deal with these issues, Tsinghua College researchers and Zhipu AI proposed the T1 technique. It enhances reinforcement studying by increasing the exploration scope and bettering inference scaling. T1 begins with coaching the language mannequin based mostly on chain-of-thought information with trial-and-error and self-verification. That is usually denied throughout the coaching part by current strategies. Thus, the mannequin finds the proper solutions and understands the steps taken to get to them. In contrast to earlier approaches centered on getting the precise options, T1 encourages numerous reasoning paths by producing a number of responses to every immediate and analyzing errors earlier than reinforcement studying. This framework enhances RL coaching in two methods: first, by oversampling, which will increase response variety, and second, by regulating coaching stability by an entropy-based auxiliary loss. Fairly than sustaining a set reference mannequin, T1 dynamically updates the reference mannequin utilizing exponential transferring averages in order that coaching can’t develop into inflexible. T1 punishes redundant, overly lengthy, or low-quality solutions with a unfavorable reward, conserving the mannequin on observe to significant reasoning.
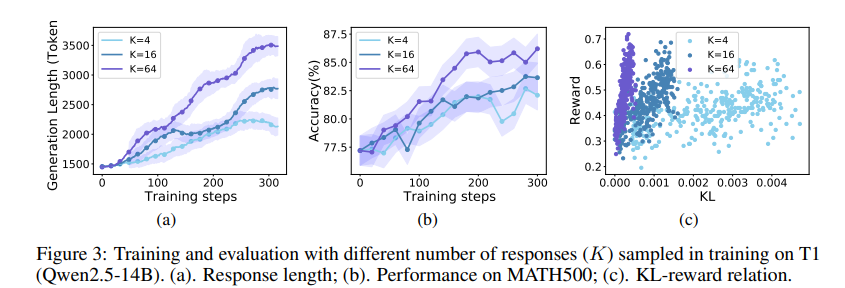
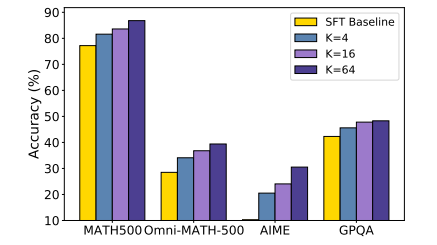
Researchers constructed T1 utilizing open fashions like GLM-4-9B and Qwen2.5-14B/32B, specializing in mathematical reasoning by reinforcement studying (RL). They derived coaching information from MATH-train and NuminaMath, curating 30,000 cases by extracting solutions and filtering noisy information. The supervised fine-tuning (SFT) used cosine decay scheduling, and RL coaching concerned coverage gradient descent with rewards based mostly on correctness. Upon analysis, T1 outperformed its baseline fashions in math benchmarks, with Qwen2.5-32B displaying a 10-20% enchancment over the SFT model. Growing the variety of sampled responses (Okay) enhanced exploration and generalization, particularly for GPQA. A sampling temperature 1.2 stabilized coaching, whereas excessively excessive or low values led to efficiency points. Penalties had been utilized throughout RL coaching to regulate response size and enhance consistency. The outcomes demonstrated important efficiency features with inference scaling, the place extra computational assets led to higher outcomes.
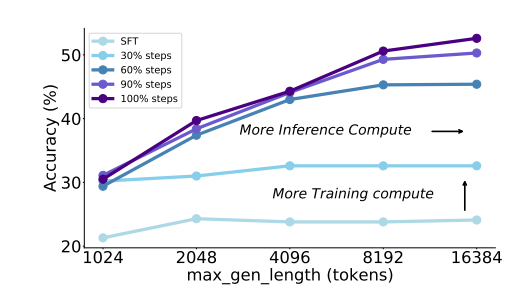
In conclusion, the proposed technique T1 enhanced giant language fashions by scaled reinforcement studying with exploration and stability. Penalties and oversampling may clean out the affect of bottlenecked samples. It confirmed sturdy efficiency and promising scaling habits. The method to measuring inference scaling confirmed that additional RL coaching improved reasoning accuracy and scaling developments. T1 surpasses state-of-the-art fashions on difficult benchmarks, overcoming weaknesses in present reasoning approaches. This work is usually a place to begin for additional analysis, providing a framework to advance reasoning capabilities and scaling giant language fashions.
Take a look at the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Overlook to affix our 75k+ ML SubReddit.
🚨 Meet IntellAgent: An Open-Supply Multi-Agent Framework to Consider Advanced Conversational AI System (Promoted)
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Expertise, Kharagpur. He’s a Knowledge Science and Machine studying fanatic who needs to combine these main applied sciences into the agricultural area and clear up challenges.
")




")


{kind=link}