

Chain-of-Thought (CoT) prompting allows giant language fashions (LLMs) to carry out step-by-step logical deductions in pure language. Whereas this technique has confirmed efficient, pure language will not be essentially the most environment friendly medium for reasoning. Research point out that human mathematical reasoning doesn’t primarily depend on language processing, suggesting that different approaches might improve efficiency. Researchers purpose to refine how LLMs course of reasoning, balancing accuracy with computational effectivity.
The problem of reasoning in LLMs stems from their reliance on express CoT, which requires producing detailed explanations earlier than arriving at a remaining reply. This strategy will increase computational overhead and slows down inference. Implicit CoT strategies try to internalize reasoning with out producing express reasoning tokens, however these strategies have traditionally underperformed in comparison with express CoT. A serious impediment lies in designing fashions that may effectively course of reasoning internally whereas sustaining accuracy. An answer that eliminates extreme computational burden with out sacrificing efficiency is vital for scaling up reasoning capabilities in LLMs.
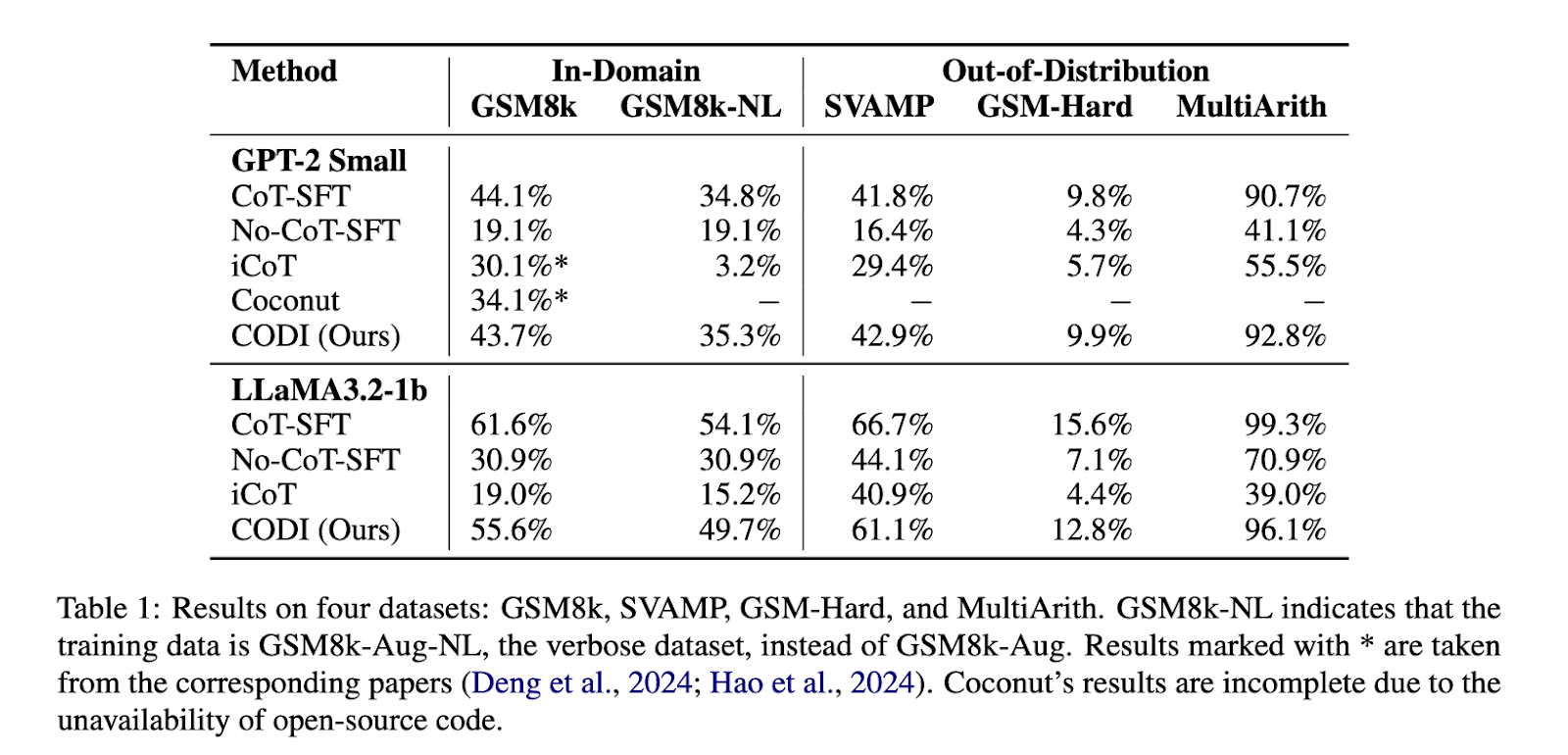
Earlier implicit CoT strategies have primarily relied on curriculum studying methods, which progressively internalize reasoning steps. One such technique, Coconut, progressively replaces express CoT tokens with steady representations whereas sustaining a language modeling goal. Nonetheless, this strategy has limitations, together with error propagation and gradual forgetting throughout coaching. In consequence, Coconut, regardless of enhancements over baseline fashions, nonetheless lags behind express CoT strategies by a big margin. Implicit CoT approaches have persistently did not match the reasoning efficiency of explicitly generated CoT.
Researchers from King’s School London and The Alan Turing Institute launched CODI (Steady Chain-of-Thought through Self-Distillation) as a novel framework to deal with these limitations. CODI distills express CoT reasoning right into a steady area, permitting LLMs to carry out logical deductions internally with out producing express CoT tokens. The strategy employs self-distillation, the place a single mannequin capabilities as each a trainer and a scholar, aligning their hidden activations to encode reasoning inside a compact latent area. By leveraging this system, CODI successfully compresses reasoning with out sacrificing efficiency.
CODI consists of two key studying duties: express CoT era and steady CoT reasoning. The trainer mannequin follows customary CoT studying by processing pure language step-by-step reasoning and producing express CoT sequences. The coed mannequin, in distinction, learns to internalize reasoning inside a compact latent illustration. To make sure correct data switch, CODI enforces alignment between these two processes utilizing an L1 distance loss perform. Not like earlier approaches, CODI immediately injects reasoning supervision into the hidden states of the mannequin, permitting for extra environment friendly coaching. As a substitute of counting on a number of coaching phases, CODI applies a single-step distillation strategy, guaranteeing that info loss and forgetting points inherent in curriculum studying are minimized. The method entails deciding on a particular hidden token that encodes essential reasoning info, offering the mannequin can successfully generate steady reasoning steps with out express tokens.
Experimental outcomes show that CODI considerably outperforms earlier implicit CoT strategies and is the primary to match the accuracy of express CoT in mathematical reasoning duties. On the GSM8k dataset, CODI achieves a 3.1× compression ratio whereas sustaining efficiency akin to express CoT. It surpasses Coconut by 28.2% in accuracy. Additional, CODI is scalable and adaptable to numerous CoT datasets, making it appropriate for extra complicated reasoning issues. Efficiency benchmarks point out that CODI achieves a reasoning accuracy of 43.7% on GSM8k with a GPT-2 mannequin, in comparison with 34.1% with Coconut. When examined on bigger fashions resembling LLaMA3.2-1b, CODI attains 55.6% accuracy, demonstrating its potential to scale successfully. Relating to effectivity, CODI processes reasoning steps 2.7 instances quicker than conventional CoT and 5.9 instances quicker when utilized to extra verbose reasoning datasets. Its strong design permits it to generalize to out-of-domain benchmarks, outperforming CoT-SFT on datasets resembling SVAMP and MultiArith.

CODI marks a big enchancment in LLM reasoning, successfully bridging the hole between express CoT and computational effectivity. Leveraging self-distillation and steady representations introduces a scalable strategy to AI reasoning. The mannequin retains interpretability, as its steady ideas could be decoded into structured reasoning patterns, offering transparency within the decision-making course of. Future analysis might discover CODI’s software in additional complicated multimodal reasoning duties, increasing its advantages past mathematical problem-solving. The framework establishes implicit CoT as a computationally environment friendly different and a viable answer for reasoning challenges in superior AI methods.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, be at liberty to observe us on Twitter and don’t overlook to affix our 80k+ ML SubReddit.
🚨 Meet Parlant: An LLM-first conversational AI framework designed to offer builders with the management and precision they want over their AI customer support brokers, using behavioral pointers and runtime supervision. 🔧 🎛️ It’s operated utilizing an easy-to-use CLI 📟 and native consumer SDKs in Python and TypeScript 📦.
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.



: A New Attention Method which Allows LLMs to Condition their Attention Weights on Multiple Query and Key Vectors")





{kind=link}