

Transformers have reworked synthetic intelligence, providing unmatched efficiency in NLP, laptop imaginative and prescient, and multi-modal knowledge integration. These fashions excel at figuring out patterns inside knowledge via their consideration mechanisms, making them very best for advanced duties. Nevertheless, the fast scaling of transformer fashions must be improved due to the excessive computational price related to their conventional construction. As these fashions develop, they demand important {hardware} assets and coaching time, which will increase exponentially with mannequin dimension. Researchers have aimed to handle these limitations by innovating extra environment friendly strategies to handle and scale transformer fashions with out sacrificing efficiency.
The first impediment in scaling transformers lies within the fastened parameters inside their linear projection layers. This static construction limits the mannequin’s skill to broaden with out being completely retrained, which turns into exponentially dearer as mannequin sizes enhance. These conventional fashions sometimes demand complete retraining when architectural modifications happen, reminiscent of rising channel dimensions. Consequently, the computational price for these expansions grows impractically excessive, and the strategy lacks flexibility. The lack so as to add new parameters dynamically stifles development, rendering these fashions much less adaptable to evolving AI functions and extra pricey when it comes to time and assets.
Traditionally, approaches to managing mannequin scalability included duplicating weights or restructuring fashions utilizing strategies like Net2Net, the place duplicating neurons broaden layers. Nevertheless, these approaches usually disrupt the steadiness of pre-trained fashions, leading to slower convergence charges and extra coaching complexities. Whereas these strategies have made incremental progress, they nonetheless face limitations in preserving mannequin integrity throughout scaling. Transformers rely closely on static linear projections, making parameter enlargement costly and rigid. Conventional fashions like GPT and different giant transformers usually retrain from scratch, incurring excessive computational prices with every new scaling stage.
Researchers on the Max Planck Institute, Google, and Peking College developed a brand new structure referred to as Tokenformer. This mannequin essentially reimagines transformers by treating mannequin parameters as tokens, permitting for dynamic interactions between tokens and parameters. On this framework, Tokenformer introduces a novel part referred to as the token-parameter consideration (Pattention) layer, which facilitates incremental scaling. The mannequin can add new parameter tokens with out retraining, drastically decreasing coaching prices. By representing enter tokens and parameters inside the identical framework, Tokenformer permits for versatile scaling, offering researchers with a extra environment friendly, resource-conscious mannequin structure that retains scalability and excessive efficiency.
Tokenformer’s Pattention layer makes use of enter tokens as queries, whereas mannequin parameters function keys and values, which differ from the usual transformer strategy, relying solely on linear projections. The mannequin’s scaling is achieved by including new key-value parameter pairs, retaining enter and output dimensions fixed, and avoiding full retraining. Tokenformer’s structure is designed to be modular, enabling researchers to broaden the mannequin seamlessly by incorporating extra tokens. This incremental scaling functionality helps the environment friendly reuse of pre-trained weights whereas enabling fast adaptation for brand new datasets or bigger mannequin sizes with out disrupting discovered info.
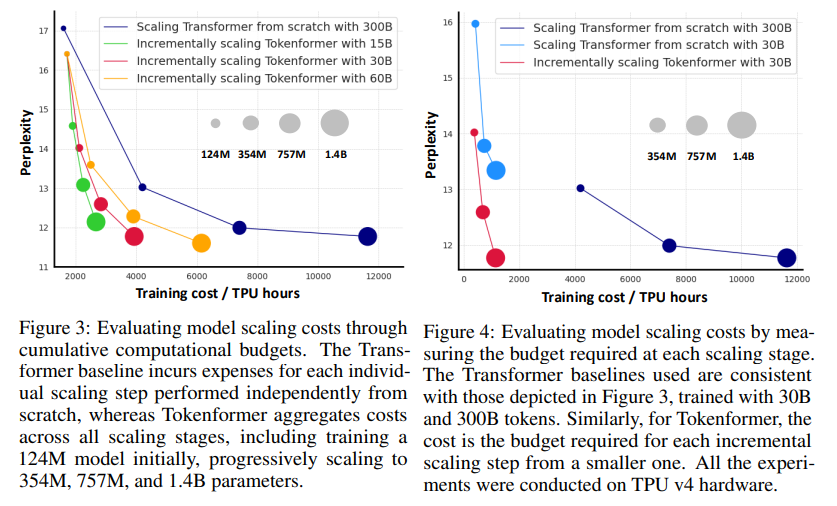
The efficiency advantages of Tokenformer are notable, because the mannequin considerably reduces computational prices whereas sustaining accuracy. As an illustration, Tokenformer scaled from 124 million to 1.4 billion parameters with solely half the everyday coaching prices conventional transformers require. In a single experiment, the mannequin achieved a check perplexity of 11.77 for a 1.4 billion parameter configuration, practically matching the 11.63 perplexity of a equally sized transformer skilled from scratch. This effectivity means Tokenformer can obtain excessive efficiency throughout a number of domains, together with language and visible modeling duties, at a fraction of the useful resource expenditure of conventional fashions.
Tokenformer presents quite a few key takeaways for advancing AI analysis and enhancing transformer-based fashions. These embody:
Substantial Price Financial savings: Tokenformer’s structure diminished coaching prices by greater than 50% in comparison with normal transformers. As an illustration, scaling from 124M to 1.4B parameters required solely a fraction of the funds for scratch-trained transformers.
Incremental Scaling with Excessive Effectivity: The mannequin helps incremental scaling by including new parameter tokens with out modifying core structure, permitting flexibility and diminished retraining calls for.
Preservation of Realized Info: The tokenformer retains data from smaller, pre-trained fashions, accelerating convergence and stopping the lack of discovered info throughout scaling.
Enhanced Efficiency on Various Duties: In benchmarks, Tokenformer achieved aggressive accuracy ranges throughout language and visible modeling duties, exhibiting its functionality as a flexible foundational mannequin.
Optimized Token Interplay Price: By decoupling token-token interplay prices from scaling, Tokenformer can extra effectively handle longer sequences and bigger fashions.

In conclusion, Tokenformer provides a transformative strategy to scaling transformer-based fashions. This mannequin structure achieves scalability and useful resource effectivity by treating parameters as tokens, decreasing prices, and preserving mannequin efficiency throughout duties. This flexibility represents a breakthrough in transformer design, offering a mannequin that may adapt to the calls for of advancing AI functions with out retraining. Tokenformer’s structure holds promise for future AI analysis, providing a pathway to develop large-scale fashions sustainably and effectively.
Take a look at the Paper, GitHub Web page, and Fashions on HuggingFace. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our e-newsletter.. Don’t Overlook to affix our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Analysis/Product/Webinar with 1Million+ Month-to-month Readers and 500k+ Group Members
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is enthusiastic about making use of know-how and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.







{kind=link}