

Speech synthesis has turn out to be a transformative analysis space, specializing in creating pure and synchronized audio outputs from numerous inputs. Integrating textual content, video, and audio information gives a extra complete method to imitate human-like communication. Advances in machine studying, significantly transformer-based architectures, have pushed improvements, enabling purposes like cross-lingual dubbing and personalised voice synthesis to thrive.
A persistent problem on this area is precisely aligning speech with visible and textual cues. Conventional strategies, akin to cropped lip-based speech technology or text-to-speech (TTS) fashions, have limitations. These approaches typically need assistance sustaining synchronization and naturalness in assorted eventualities, akin to multilingual settings or advanced visible contexts. This bottleneck limits their usability in real-world purposes requiring excessive constancy and contextual understanding.
Present instruments rely closely on single-modality inputs or advanced architectures for multimodal fusion. For instance, lip-detection fashions use pre-trained techniques to crop enter movies, whereas some text-based techniques course of solely linguistic options. Regardless of these efforts, the efficiency of those fashions stays suboptimal, as they typically fail to seize broader visible and textual dynamics important for pure speech synthesis.
Researchers from Apple and the College of Guelph have launched a novel multimodal transformer mannequin named Visatronic. This unified mannequin processes video, textual content, and speech information by means of a shared embedding area, leveraging autoregressive transformer capabilities. Not like conventional multimodal architectures, Visatronic eliminates lip-detection pre-processing, providing a streamlined resolution for producing speech aligned with textual and visible inputs.
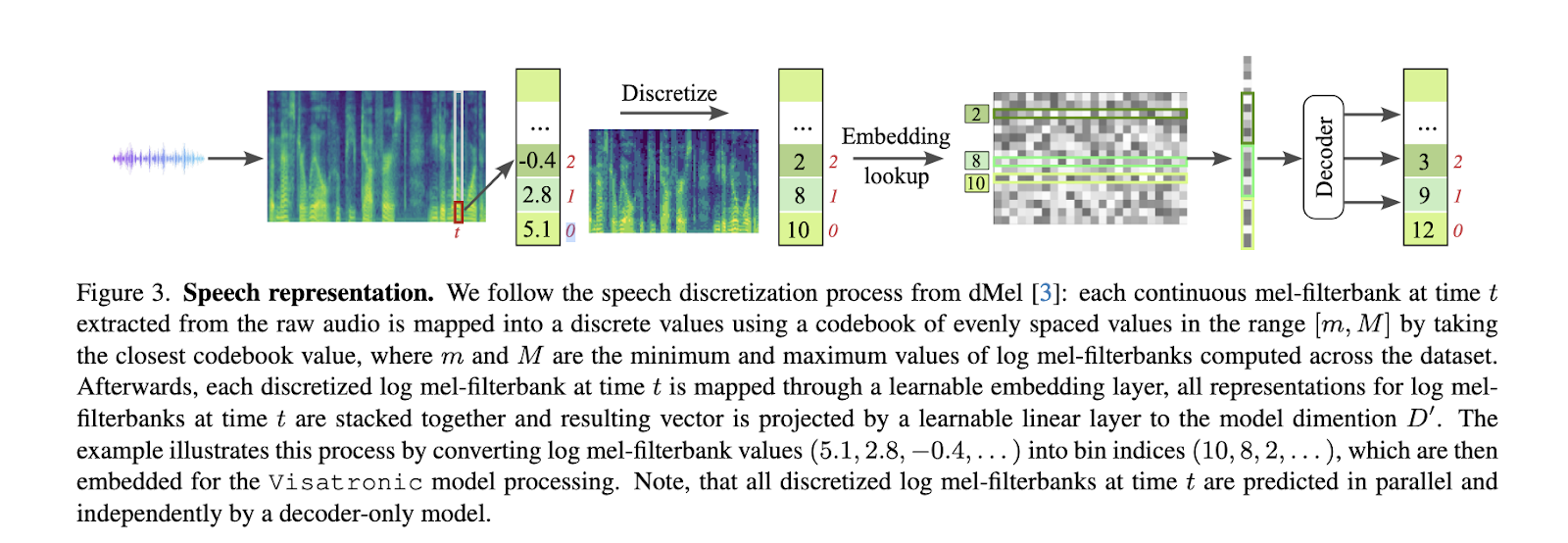
The methodology behind Visatronic is constructed on embedding and discretizing multimodal inputs. A vector-quantized variational autoencoder (VQ-VAE) encodes video inputs into discrete tokens, whereas speech is quantized into mel-spectrogram representations utilizing dMel, a simplified discretization method. Textual content inputs endure character-level tokenization, which improves generalization by capturing linguistic subtleties. These modalities are built-in right into a single transformer structure that permits interactions throughout inputs by means of self-attention mechanisms. The mannequin employs temporal alignment methods to synchronize information streams with assorted resolutions, akin to video at 25 frames per second and speech sampled at 25ms intervals. Moreover, the system incorporates relative positional embeddings to keep up temporal coherence throughout inputs. Cross-entropy loss is utilized completely to speech representations throughout coaching, guaranteeing strong optimization and cross-modal studying.
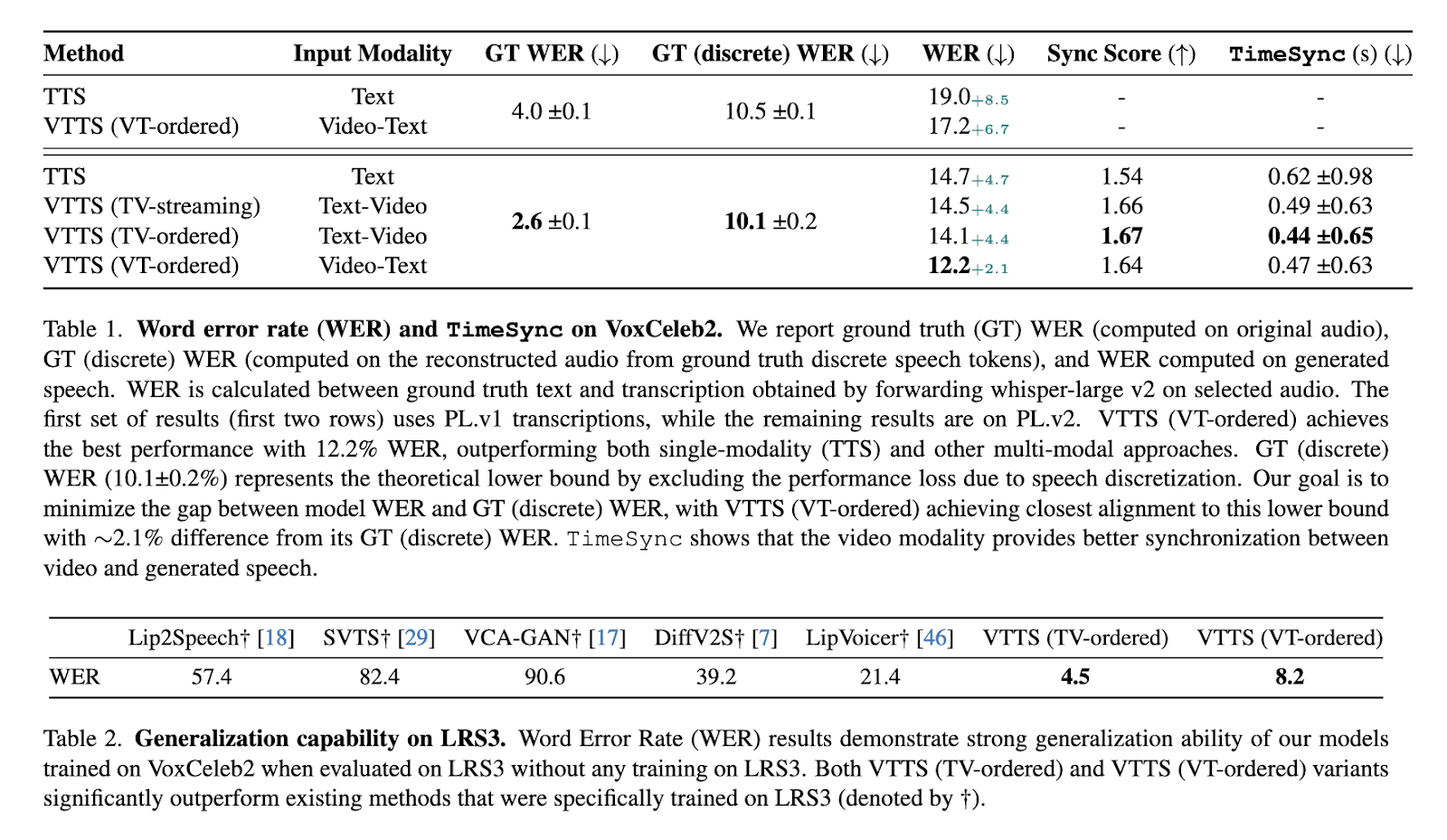
Visatronic demonstrated important developments in efficiency on difficult datasets. On the VoxCeleb2 dataset, which incorporates numerous and noisy circumstances, the mannequin achieved a Phrase Error Price (WER) of 12.2%, outperforming earlier approaches. It additionally attained 4.5% WER on the LRS3 dataset with out further coaching, showcasing sturdy generalization capabilities. In distinction, conventional TTS techniques scored greater WERs and lacked the synchronization precision required for advanced duties. Subjective evaluations additional confirmed these findings, with Visatronic scoring greater intelligibility, naturalness, and synchronization than benchmarks. The VTTS (video-text-to-speech) ordered variant achieved a imply opinion rating (MOS) of three.48 for intelligibility and three.20 for naturalness, outperforming fashions skilled solely on textual inputs.
The combination of video modality not solely improved content material technology but in addition diminished coaching time. For instance, Visatronic variants achieved comparable or higher efficiency after two million coaching steps in comparison with three million for text-only fashions. This effectivity highlights the complementary worth of mixing modalities, as textual content contributes content material precision whereas video enhances contextual and temporal alignment.
In conclusion, Visatronic represents a breakthrough in multimodal speech synthesis by addressing key challenges of naturalness and synchronization. Its unified transformer structure seamlessly integrates video, textual content, and audio information, delivering superior efficiency throughout numerous circumstances. This innovation, developed by researchers at Apple and the College of Guelph, units a brand new commonplace for purposes starting from video dubbing to accessible communication applied sciences, paving the way in which for future developments within the area.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our e-newsletter.. Don’t Neglect to hitch our 55k+ ML SubReddit.
🎙️ 🚨 ‘Analysis of Giant Language Mannequin Vulnerabilities: A Comparative Evaluation of Purple Teaming Methods’ Learn the Full Report (Promoted)
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.




 | by Sandi Besen | Dec, 2024")


