

Fixing sequential duties requiring a number of steps poses important challenges in robotics, notably in real-world purposes the place robots function in unsure environments. These environments are sometimes stochastic, which means robots face variability in actions and observations. A core objective in robotics is to enhance the effectivity of robotic programs by enabling them to deal with long-horizon duties, which require sustained reasoning over prolonged durations of time. Determination-making is additional sophisticated by robots’ restricted sensors and partial observability of their environment, which prohibit their potential to know their surroundings fully. Consequently, researchers constantly search new strategies to boost how robots understand, study, and act, making robots extra autonomous and dependable.
Researchers’ main downside on this space facilities round a robotic’s lack of ability to study from previous actions effectively. Robots depend on strategies like reinforcement studying (RL) to enhance efficiency. Nonetheless, RL requires many trials, usually within the thousands and thousands, for a robotic to change into proficient at finishing duties. That is impractical, particularly in partially observable environments the place robots can’t work together constantly as a result of related dangers. Furthermore, current programs, corresponding to decision-making fashions powered by massive language fashions (LLMs), battle to retain previous interactions, forcing robots to repeat errors or relearn methods they’ve already encountered. This lack of ability to use prior data hinders their effectiveness in advanced, long-term duties.
Whereas RL and LLM-based brokers have proven promise, they exhibit a number of limitations. Reinforcement studying, as an illustration, is very data-intensive and calls for important guide effort for designing reward capabilities. Alternatively, LLM-based brokers, that are used for producing motion sequences, usually lack the flexibility to refine their actions primarily based on previous experiences. Current strategies have included critics to judge the feasibility of choices. Nonetheless, they nonetheless fall brief in a single crucial space: the flexibility to retailer and retrieve helpful data from previous interactions. This hole implies that whereas these programs can carry out nicely in short-term or static duties, their efficiency degrades in dynamic environments, requiring continuous studying and adaptation.
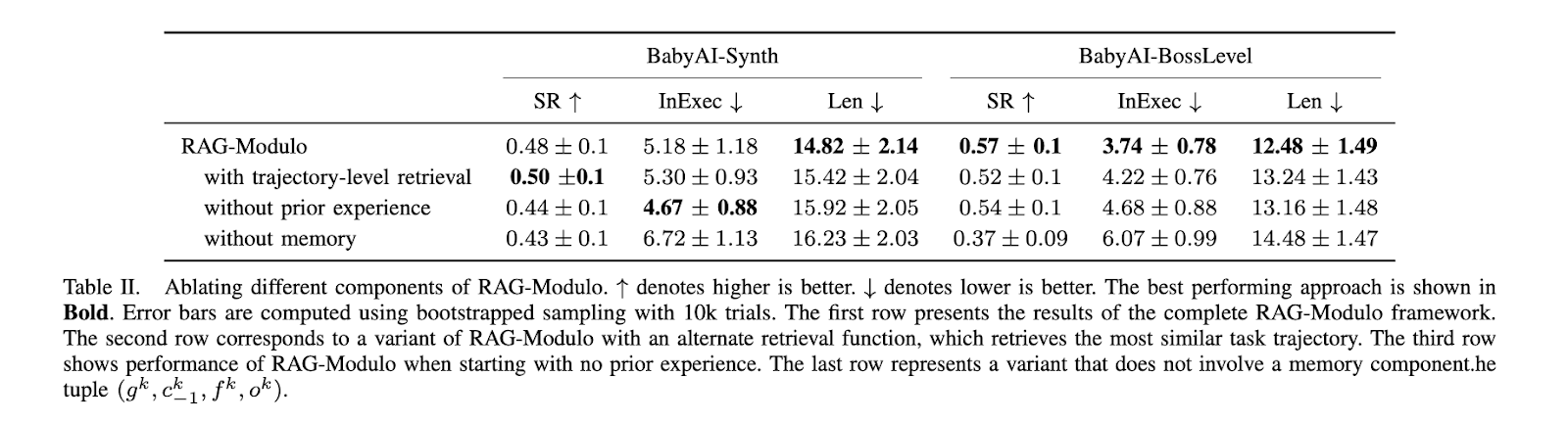
Researchers from Rice College have launched the RAG-Modulo framework. This novel system enhances LLM-based brokers by equipping them with an interplay reminiscence. This reminiscence shops previous selections, permitting robots to recall and apply related experiences when confronted with comparable duties sooner or later. By doing so, the system improves decision-making capabilities over time. Additional, the framework makes use of a set of critics to evaluate the feasibility of actions, providing suggestions primarily based on syntax, semantics, and low-level coverage. These critics make sure that the robotic’s actions are executable and contextually acceptable. Importantly, this strategy eliminates the necessity for intensive guide tuning, because the reminiscence routinely adapts and tunes prompts for the LLM primarily based on previous experiences.
The RAG-Modulo framework maintains a dynamic reminiscence of the robotic’s interactions, enabling it to retrieve previous actions and outcomes as in-context examples. When going through a brand new activity, the framework attracts upon this reminiscence to information the robotic’s decision-making course of, thus avoiding repeated errors and enhancing effectivity. The critics embedded inside the system act as verifiers, offering real-time suggestions on the viability of actions. For instance, if a robotic makes an attempt to carry out an infeasible motion, corresponding to choosing up an object in an occupied area, the critics will recommend corrective steps. Because the robotic continues to carry out duties, its reminiscence expands, changing into extra able to dealing with more and more advanced sequences. This strategy ensures continuous studying with out frequent reprogramming or human intervention.
The efficiency of RAG-Modulo has been rigorously examined in two benchmark environments: BabyAI and AlfWorld. The system demonstrated a marked enchancment over baseline fashions, attaining larger success charges and lowering the variety of infeasible actions. In BabyAI-Synth, as an illustration, RAG-Modulo achieved a hit charge of 57%, whereas the closest competing mannequin, LLM-Planner, reached solely 43%. The efficiency hole widened within the extra advanced BabyAI-BossLevel, the place RAG-Modulo attained a 57% success charge in comparison with LLM-Planner’s 37%. Equally, within the AlfWorld surroundings, RAG-Modulo exhibited superior decision-making effectivity, with fewer failed actions and shorter activity completion instances. Within the AlfWorld-Seen surroundings, the framework achieved a median in-executability charge of 0.09 in comparison with 0.16 for LLM-Planner. These outcomes reveal the system’s potential to generalize from prior experiences and optimize robotic efficiency.
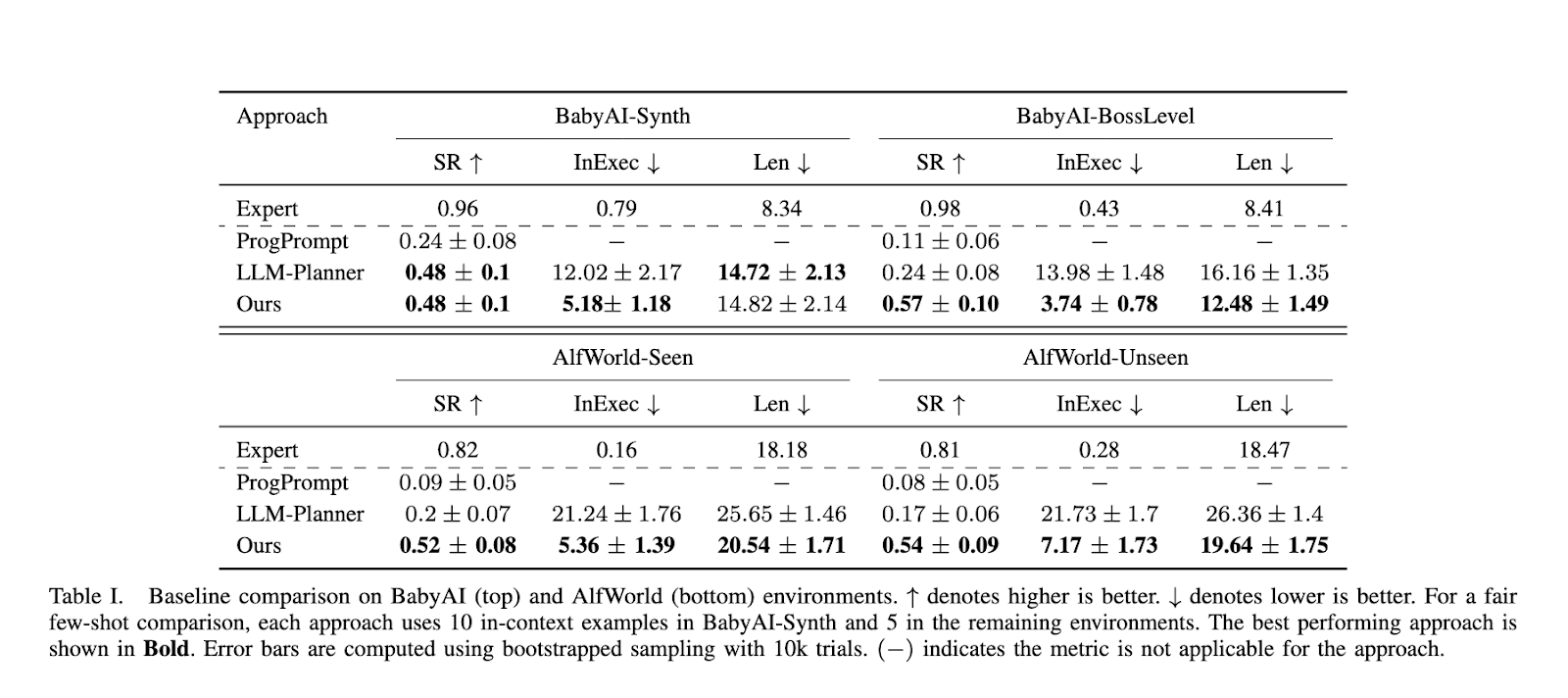
Relating to activity execution, RAG-Modulo additionally lowered the typical episode size, highlighting its potential to perform duties extra effectively. In BabyAI-Synth, the typical episode size was 12.48 steps, whereas different fashions required over 16 steps to finish the identical duties. This discount in episode size is critical as a result of it will increase operational effectivity and lowers the computational prices related to working the language mannequin for longer durations. By shortening the variety of actions wanted to realize a objective, the framework reduces the general complexity of activity execution whereas guaranteeing that the robotic learns from each choice it makes.
The RAG-Modulo framework presents a considerable leap ahead in enabling robots to study from previous interactions and apply this data to future duties. By addressing the crucial problem of reminiscence retention in LLM-based brokers, the system gives a scalable resolution for dealing with advanced, long-horizon duties. Its potential to couple reminiscence with real-time suggestions from critics ensures that robots can constantly enhance with out requiring extreme guide intervention. This development marks a big step towards extra autonomous, clever robotic programs able to studying and evolving in real-world environments.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our publication..
Don’t Overlook to hitch our 50k+ ML SubReddit
⏩ ⏩ FREE AI WEBINAR: ‘SAM 2 for Video: The way to Positive-tune On Your Knowledge’ (Wed, Sep 25, 4:00 AM – 4:45 AM EST)
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.








{kind=link}